Cały wpis został przerobiony 
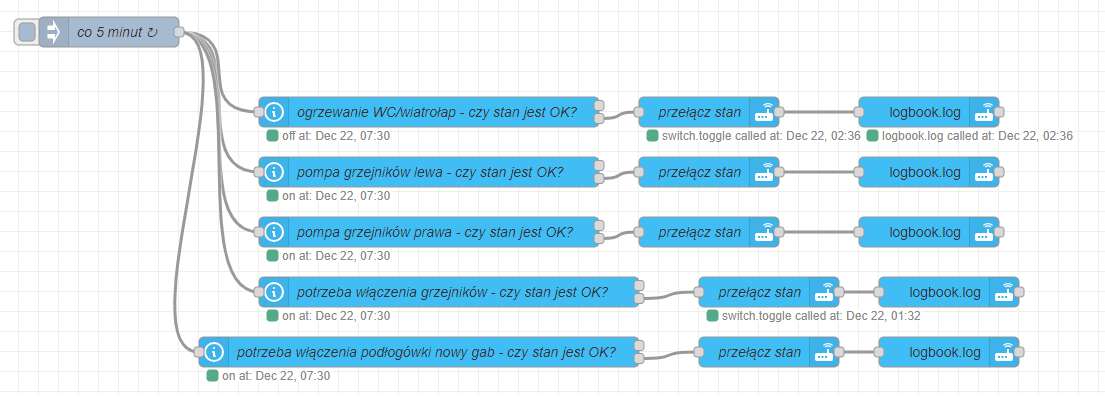
Wersja pierwotna była taka…
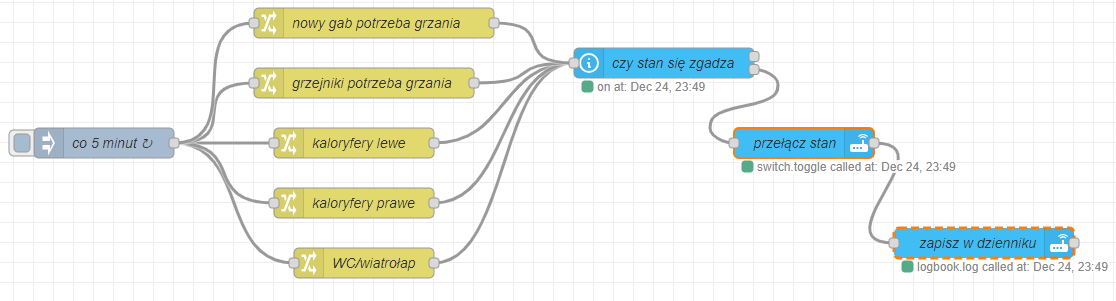
a po zmianach przybrała formę:
Cała idea zasadza się, by “wstrzyknąć” entity_id obiektów, których stan będzie synchronizowany.
-
Automat uruchamia co 5 minut sprawdzanie
-
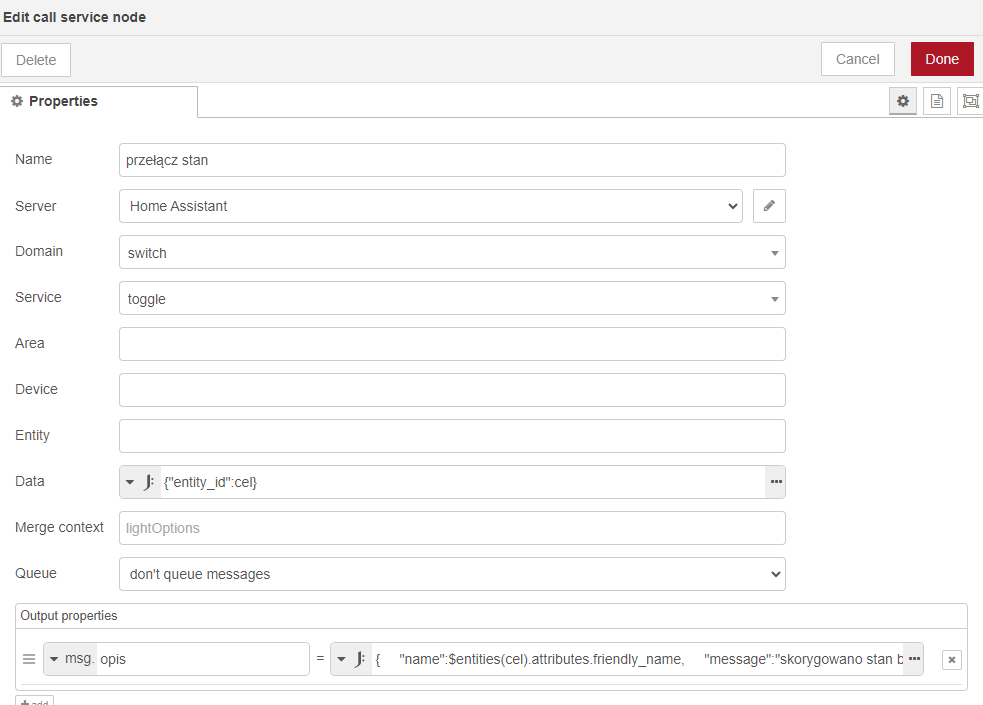
Sygnał trafia do węzła, w którym definiowane są dwa elementy: zrodlo i cel (irytowało mnie source i target, polskich literek lepiej unikać bo się czasem coś potrafi wykrzaczyć).
-
Następny węzeł odczytuje z wiadomości pola zrodlo i cel i porównuje stany tych encji.
-
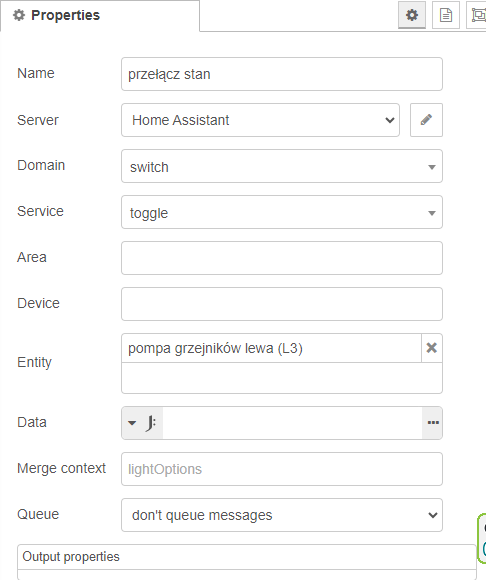
Jeśli się różnią (wyjście dolne) to wywoływane jest switch toggle (możliwe są 2 stany, skoro się różnią to po zmianie jednego będą zgodne). Tutaj też generowany jest wsad do loggera. Odnośnie toggle vs turn_on/turn_off przemyślenia na końcu.
-
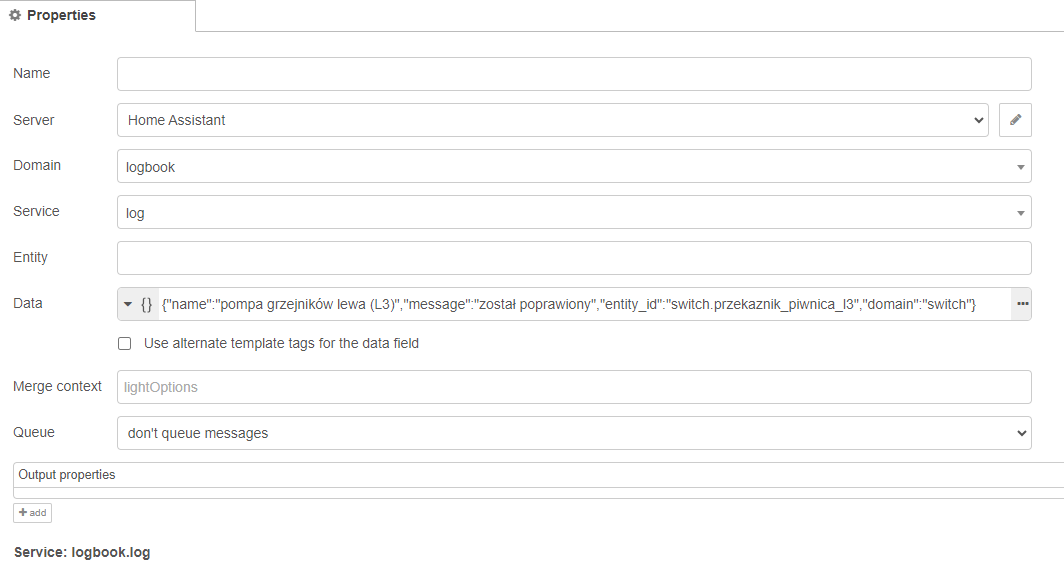
Logbook.log zapisuje gotowy wsad nic nie modyfikując.
Po przeróbkach wygląda to następująco:
Wybieramy, co jest źródłem, a co celem synchronizacji
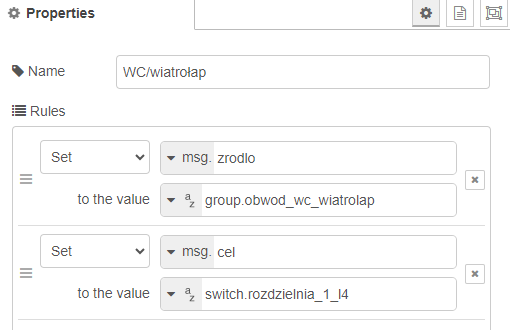
Jakie to ma praktyczne konsekwencje? Przede wszystkim upraszcza dodawanie kolejnych zestawów i eliminuje szansę, że się walnę robiąc jakąś literówkę
Tak więc sprawdźmy, czy mamy powody by coś przełączać
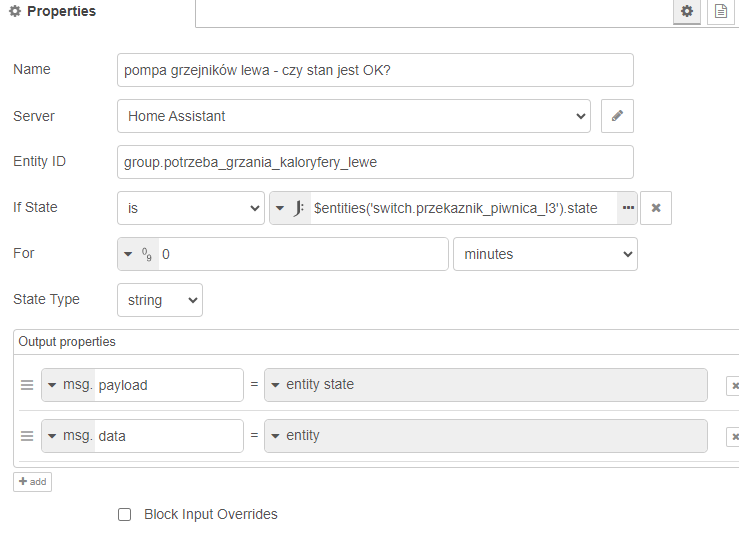
sprawdzanie ze sztywno wpisanymi formułami
encje “zaszyte” w strumieniu danych
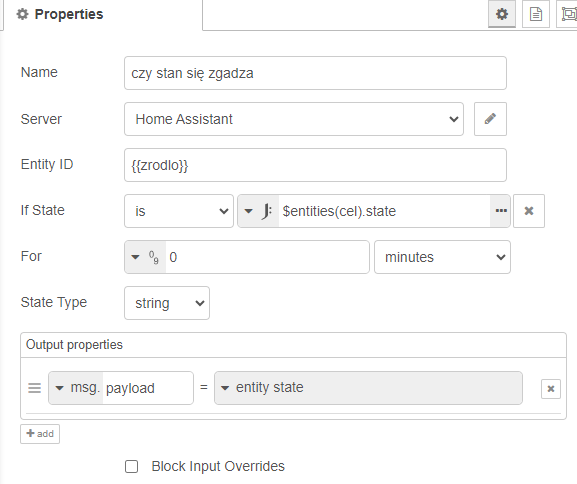
po prostu sprawdzamy czy stan źródła i stan celu są sobie równe nie przejmując się co konkretnie jest czym - przecież to już przypisaliśmy. 
Jeśli stany nie są sobie równe, to co należy zrobić? Przełączyć…
ale można to zrobić “po staremu” ręcznie zaszywając encje:
lub ponownie zdając się na “zaszyte” dane:
Tutaj miał miejsce jeden zgrzyt: węzeł wymaga podania encji, ale po wpisaniu w pole entity wartości
{{cel}} aby system podstawił i zapisaniu wartość znika - stąd to obejście w linijce data -
{"entity_id":cel}.
Być może to ja nie potrafiłem prawidłowo podać formuły… możliwe - gdzieś w necie spotkałem się, że powinno dać się zaciągnąć wszystko automatycznie, ale mi się nie udało.
Po wielu kombinacjach formułowanie opisu dla loggera ma miejsce tutaj.
{
"name":$entities(cel).attributes.friendly_name,
"message":"skorygowano stan by się zgadzało z " & $entities(zrodlo).attributes.friendly_name &" -",
"entity_id":cel,
"domain":"switch"
}
Nie jest to sytuacja idealna, ale o tym poniżej.
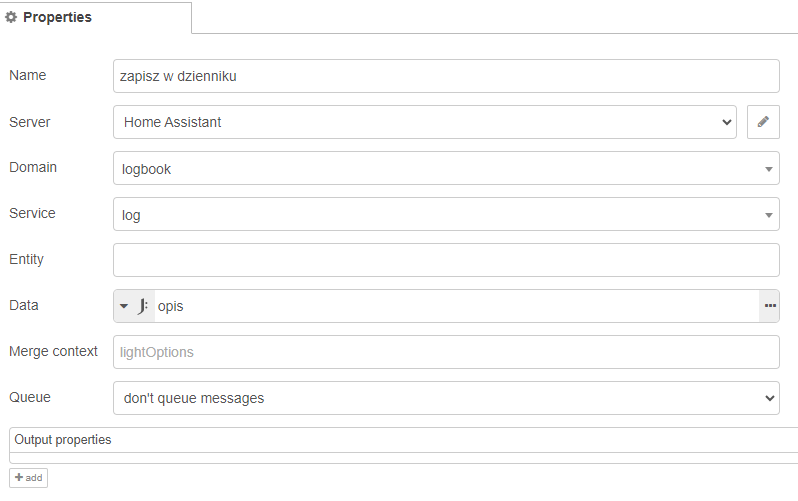
Mamy już poprawiony stan celu, więc jeszcze pozostało zrobić wpis w logu.
I ponownie możemy to zrobić metodą pracowitą:
lub zaciągnąć przygotowany obiekt “opis” i mieć z tym spokój:
Podchodziłem do sprawy bardzo idealistycznie:
- funkcyjna koncepcja programowania powoduje, że podaję obiekty a opracowana formuła sama potrafi wyłuskać potrzebne dane nie wymagając ode mnie ręcznego tuningowania.
- zasada “pojedynczej odpowiedzialności” sugeruje, by wyłączyć generowanie wpisu do własnego węzła, ale… nie udało mi się
 … Jestem w stanie wygenerować ów opis w obiekcie loggera (wystarczy dosłownie przekleić formułę) ale wtedy logger będzie “jednorazowy”. Można to zrobić na etapie filtrowania, ale po co tworzyć formułę, jeśli będzie ona potrzebna 1-2 razy w tygodniu łącznie a co 5 minut sprawdza 5 zestawów. Tak więc po długich bojach opis powstaje przy przełączaniu, ale będę próbować go wyciągnąć
… Jestem w stanie wygenerować ów opis w obiekcie loggera (wystarczy dosłownie przekleić formułę) ale wtedy logger będzie “jednorazowy”. Można to zrobić na etapie filtrowania, ale po co tworzyć formułę, jeśli będzie ona potrzebna 1-2 razy w tygodniu łącznie a co 5 minut sprawdza 5 zestawów. Tak więc po długich bojach opis powstaje przy przełączaniu, ale będę próbować go wyciągnąć
To co pozostawia mi lampki kontrolne z tyłu głowy to:
- chęć wyciągnięcia generacji opisu do oddzielnego węzła
- na ten moment przełączanie ma na stałe przypisane: domain - switch, service - toggle. Być może przydałoby się, by wsadzić tutaj domenę zassaną z taśmociągu ;-), znalazłem w necie pomysł, by service było zdefiniowane jako
turn_{{stan_zrodla}} jeśli takowy obiekt sobie wcześniej wygenerujemy (moja główna inspiracja).
I teraz w zasadzie mam tylko jeszcze wątpliwość co dalej zrobić…
Chyba wątek nadaje się, do zaznaczenia, że problem rozwiązany.
Na dobrą sprawę chyba powinienem zwinąć to wszystko do wpisu otwierającego i w zasadzie można już zmienić tytuł. Ale na to nie mam jeszcze pomysłu i pewności by nie zrobić jakiegoś faux-pas
Wolałbym tylko nie zamykać jeszcze wątku, gdyby jakaś dobra duszyczka postanowiła mi wypunktować co można zrobić lepiej, skuteczniej czy bezpieczniej.