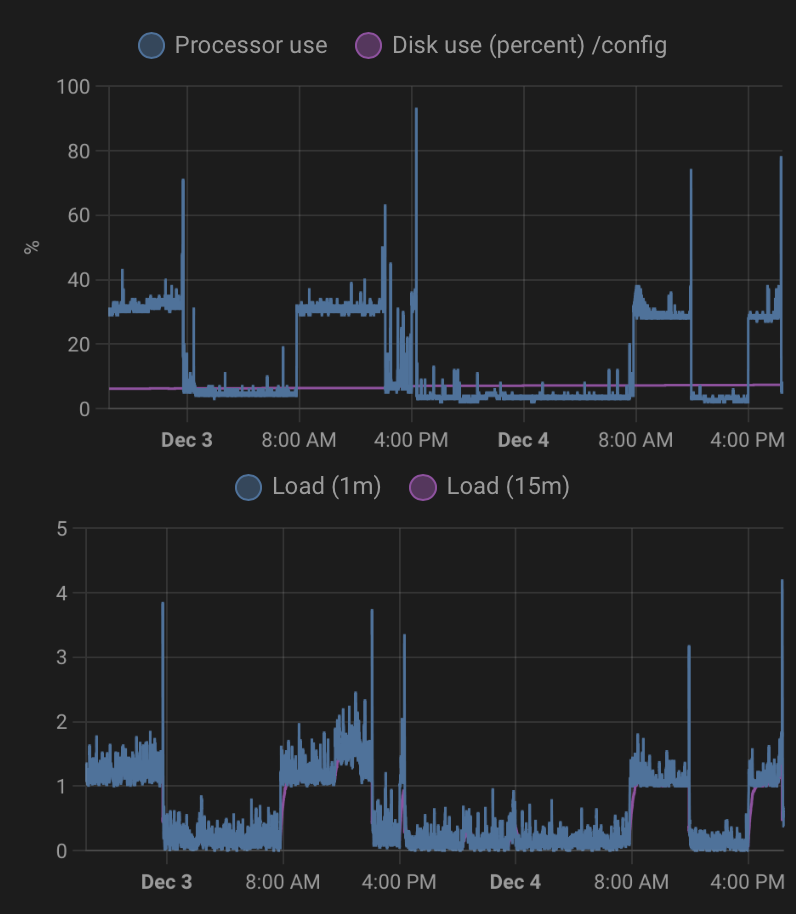
czy ktoś z Was spotkał się z takim problem: normalne zużycie CPU to ok 4-8%, lecz cykliczne o tym samych godzinach rośnie do 30-40% i nie spada aż do czasu restartu HA-VM. Instalacja ma ok 3 tyg i stoi na HP T630 (4cpu, 8gb i ssd:128). Są to moje początki z HA. Mam głównie integracje TV i Audio zrobione na Node-Red.
Wygląda mi to na jakieś cykliczne procesy albo Proxmox albo HA.
Podobne problemy były opisywane na forum wielokrotnie, w zdecydowanej większości przypadków przyczyną jest wadliwy kod uruchomiony w NR.
Przyjrzyj się godzinom pierwszego piku i porównaj z czasami wykonywania automatyzacji w NR.
W pozostałej niewielkiej ilości przypadków były to wadliwe wersje Dodatków lub Komponentów Niestandardowych.
Przyczyną może też być wadliwa instalacja VM (jeśli nie masz żadnej innej VM oprócz HAOS i nie planujesz to sugerowałbym instalację HAOS generic, czyli bare-metal bez dodatkowej wirtualizacji).
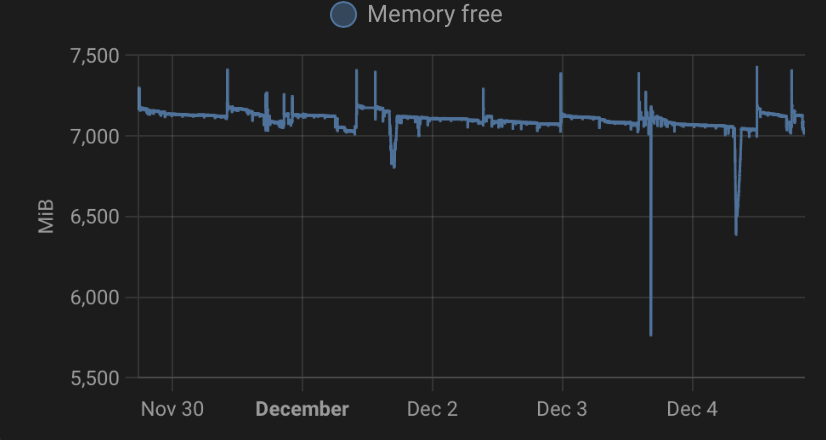
Monitorujesz też wykorzystanie RAM i swap’a (z poziomu HA, czyli “wewnątrz VM”)?
Właśnie nie widzę powiązań godzin z NR i zmianami zużycia:
radio 6:10 (pn-pt), 6:30 (sb), 6:45 (nd)
oczyszczać powietrza: codziennie 6:00 (auto mode), 21:30 (sleep mode).
Sprawdziłem też:
w czasie dużego zużycia cpu widać jakieś większe zużycie przy kompententach. Ale tutaj też pudło.
czy db z HA ma jakieś błędy - tez wszystko ok.
Zainstalowałem właśnie Glance i będę coś wiedział więcej po nocy.
T630 będzie mi służył tylko do HA i nie planuje nic innego.
Wklejałeś to na jakimś innym forum i to jest kolejna przeklejka? (tak skopanego YAMLa w poście jeszcze nie widziałem).
Użyj linijek z trzema odwrotnymi apostrofami ```
(tymi spod klawisza tyldy, a nie obok entera) przed i po wklejanym kawałku kodu (a jeśli nie wiesz jak to zrobić, to chociaż wklej jak jest a poprawię posta, teraz jest to awykonalne).
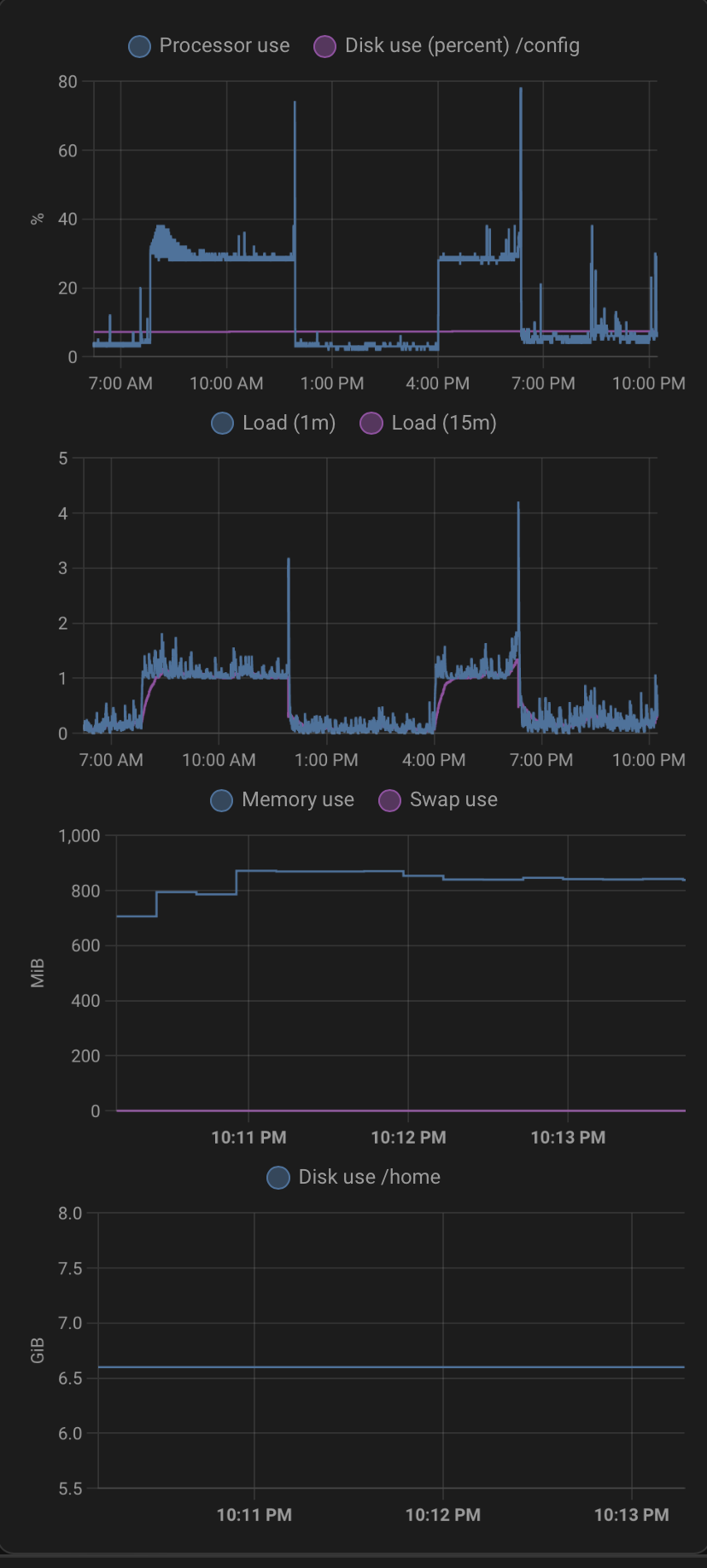
PS wrzuć pamięć i swapa na tym samym wykresie co procek (obecne wartości są OK, ale warto widzieć czy jest jakiekolwiek powiązanie).
Dzięki za info (to c&p bezpośrednio z FileEditora z HA)
Chcę najpierw rozwiązać tą zagadkę na Proxmox - jak to problem z NR jak uważasz to jest szansa, że na bare-metal też się powtórzy. Jakkolwiek drugi dysk już przybywa.
To powyżej przykleiłem z File Editora (stosując linijki z odwrotnymi apostrofami).
Poprawiam dziesiątki postów osób, które nie wiedzą o tych apostrofach i wklejają “jak jest”, ale nigdy nie ma aż takich problemów (o ile posta nie widać poprawnie, to daje się to poprawić prostą edycją) - u Ciebie jest inaczej, musiałeś prawdopodobnie użyć “po drodze” jakiegoś niepoprawnego formatowania.
W tamtym poście masz coś takiego - to nijak nie wygląda jak prosto z edytora (nawalone jest od czapy gwiazdek)
Nie napisałeś jakie zasoby przeznaczyłeś na VM (proxmox też coś potrzebuje “do życia”).
Jakkolwiek to eliminuje częstą przyczynę, którą jest wyciek pamięci.
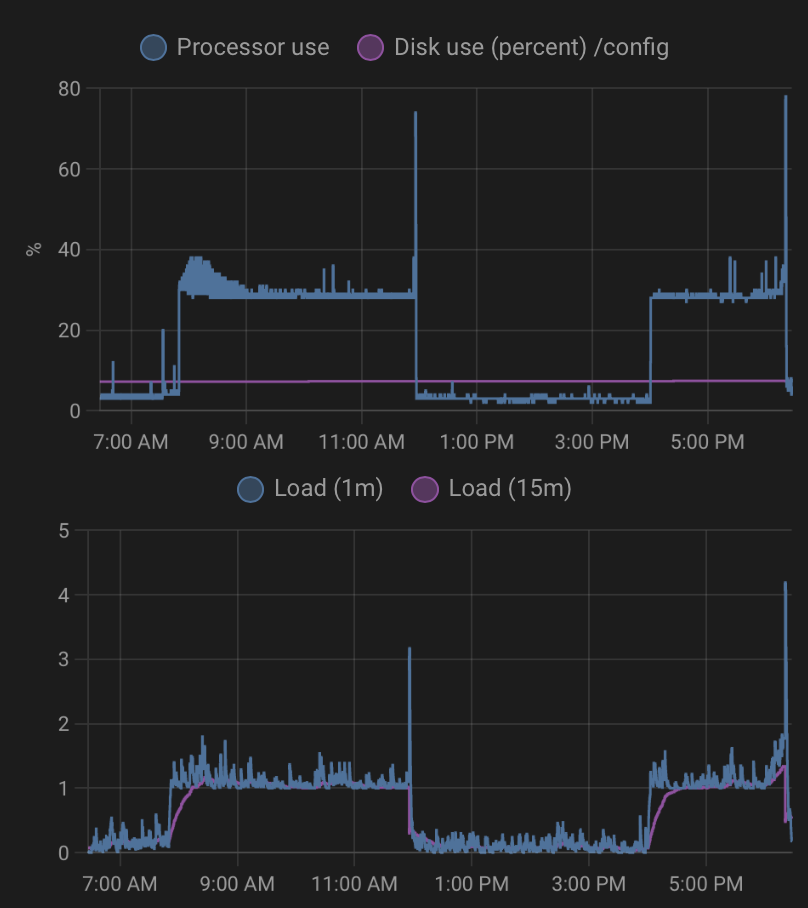
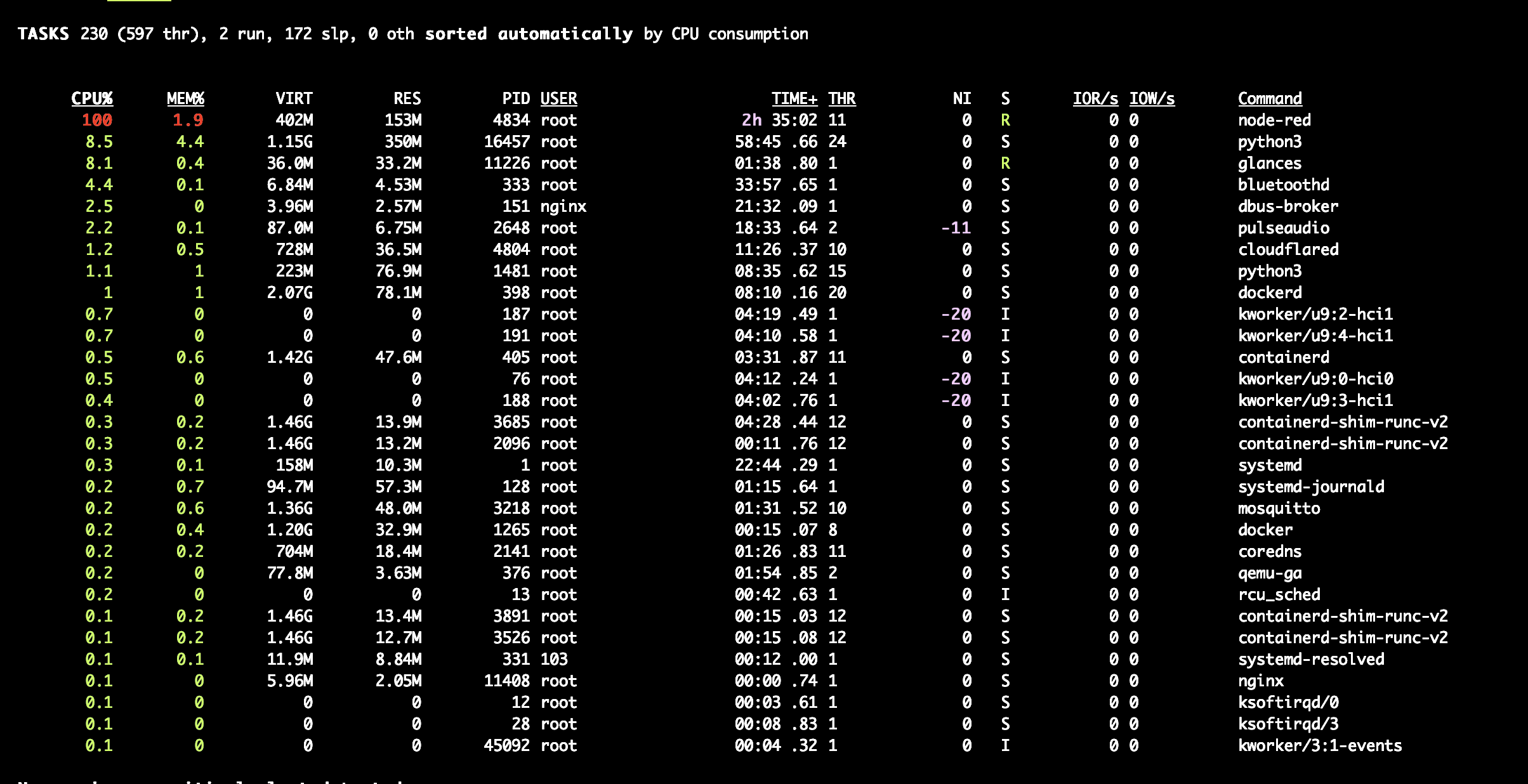
z Glances wychodzi ze node-red bierze cały jeden core. Spróbuje zreinstalować go i zobaczę co się dzieje. Zmiana z niskiego na wysokie zużycie CPU następuje ok 7:40 rano i nie jest to uzależnione od akcji włączanych o określonej godzinę (nie mam nić w tej okolicy)
Zrobiłem tak jak zasugerowało. Tak miałem kilka pętli “catch”, ale po wyłączeniu ich dalej ten sam problem się pojawiał.
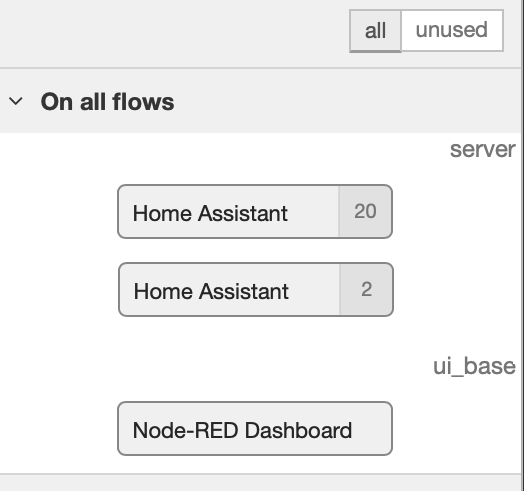
Przeglądając Flow’y przypominałem sobie, że importowałem jeden flow z swojej testowej instalacji HA. W Configuration nodes zaintrygowały mnie dwie serwery HA jak poniżej na scrshot. Po usunięciu tego z (2) wszystko zaczęło zachowywać się jak trzeba.
Więc błędem był import flow i jakieś pozostałości, które nie były widoczne.