Witajcie. To mój pierwszy post na tym forum. Uruchomiłem Atom Echo na moim HA. Problem to nieprawidłowe rozpoznawanie mowy.Jest bardzo kiepsko. Pytanie: Jakiego modelu mowy używacie? Moje ustawienia na Atom Echo są standardowe.
Model: tiny int-8, Lang: pl, Beam size 1
Może macie jakieś doświadczenia z tym urządzeniem. Bardzo proszę o opinie.
Z tego co kojarzę to wygrywają ESPHome do Atom echo i to działa.
Skrót myślowy, nie wiem co zrobiłeś i jak (“punkt widzenia zależy od punktu siedzenia”)? Może jednak warto to zrobić wg tego poradnika:
Szybki poradnik po polsku jak zrobić własne wyrażenie włączające mikrofon “Wake Word” na forum:
Oryginalna instrukcja przygotowana przez zespół HA:
Tak więc Grzegorz do dzieła ![]() , jak się uda proszę opisz swoje doświadczenia i problemy (może coś nie jest uwzględnione w instrukcjach) przy realizacji tego rozwiązania.
, jak się uda proszę opisz swoje doświadczenia i problemy (może coś nie jest uwzględnione w instrukcjach) przy realizacji tego rozwiązania.
Ale ja to wszystko mam uruchomione i działa Robiłem to w/g tego poradnika właśnie. Może źle się wyraziłem. Chodzi mi o to, że to działa badziewnie. Mam w domu dwa głośniki Google Home Mini i to urządzenie nie dorasta im do pięt. Chodzi mi dokładność rozpoznawania mojego głosu. Echo na moje wezwanie reaguje idealnie lecz gdy wydam komendę to w logach widzę jak przekręca moje słowa czego efektem jest brak reakcji. Żeby zapalić lampę muszę niejednokrotnie powtarzać komendę kilka razy aż w końcu załapie. Na koniec dodam, że rozmawiamy o naszym ojczystym języku a nie języku angielskim bo takowy mam w obsłudze Google Home Mini.
Mam działające dwa “atomy”, nie korzystam z własnej komendy tylko z wbudowanej “Ok nabu”. Wszystko spięte przez nabu cas-ę, działa to bardzo fajnie.
Nadal nie rozumiecie o co mi chodzi?
Ja też korzystam z wbudowanej komendy tyle że z “Aleksa”. Na komnde ok abu wzbudzały mi się moje Google Home mini. Chodzi mi o to, że komendy uruchamiające jakieś działanie źle działają. Przykład: Mówię “Aleksa włącz światło w kuchni” a Echo rozpoznaje (widoczne w logu) “Włąsz światło w kuchni”, “Wąt światło w kuchni” itd, itp. Efektem jest brak włączenia światła w kuchni. Zapewniam, że mówię wyraźnie. Nie posiadam żadnych wad wymowy żeby było jasne.
Rozumiem, opisałem Ci jak mam skonfigurowaną i działającą u mnie.
Edit:
Mam dwa google mini.
Nic nie napisałeś. Napisałeś tylko że korzystasz z ok nabu a to nic nie wnosi To tylko słowo wywołujące. Nie ma ono wpływu na jakość rozpoznawania mowy
Więc ja Ci odpowiem. Korzystam z M5Stack Atom Echo, używam własnego słowa wywołującego, korzystam z Nabu Casa i “rozmawiam” z głośnikiem w naszym ojczystym języku.
Mało co prawda z nim gadam, ale tak jak napisał już przedmówca, nie doświadczyłem aby czegoś nie rozpoznawał.
Natomiast porównywanie tego “głośniczka” do Google Mini jest co najmniej zabawne. To co opublikowali developerzy HA dla głośnika Atom Echo, miało na celu zademonstrowanie funkcjonalności jaka się pojawiła w systemie, czyli obsługi głosu. Najpierw z wywołaniem za pomocą przycisku w głośniku, a obecnie za pomocą słowa wywołującego.
Swoją drogą istnieją już przeróbki głośnika Google Mini (sprzętowe) umożliwiające korzystanie z niego w HA.

Onju-voice to bardzo ciekawy projekt. Przedwczoraj wpadł mi w oko. Zamówiłem ATOM Echo z myślą o testach wbudowanego w HA rozwiązania jak i tego z OpenAI. Dziś przyszedł. Wygląda to obiecująco. openWakeWord działa, do Whispera trzeba mówić głośno i z dobrą dykcją a Gosia z Pipera jeszcze się uczy czytać, np. liczbę “23,48” ![]()
edit: przepraszam Gosię, w sumie Asystent Google czyta tak samo, więc to pewnie HA źle wysyła treść do syntezatora.
Użyłeś lokalnego STT (Whisper), który jest bardzo wymagający sprzętowo. W dodatku wybrałeś najniższy model, więc nie ma prawa działać perfekcyjnie. Szczególnie nie radzi sobie z naszymi syczącymi ‘sz’, ‘cz’ itd. Na RPI4 potrafi mielić pół minuty zanim coś wypluje. Z kolei z Nabu Casa, zarówno STT jak i TTS, działają niemalże perfekcyjnie. Jeśli szukasz darmowego rozwiązania, które działa, to jako STT użyj Google Cloud i TTS lokalnego Piper’a. Google Cloud TTS nie udało mi się zaprząc do współpracy. Używa kodeków, których nie wspiera Voice Assistant z HA. Google Cloud jest generalnie płatny, ale ma darmowe limity, które powinny wystarczyć. Piper brzmi trochę sztucznie i z kiepskiego głośnika z Atom’a trochę się rwie, ale jest za darmo. Tu masz linka do Google Cloud STT GitHub - chatziko/ha-google-cloud-stt: Use Google Cloud Speech-to-Text in Home Assistant.
1 polubienie
Witam, AtomEcho i EspHome, voice assistant zainstalowany. Whisper działa nawet na najwyższym modelu bardzo kiepsko. Tak że moim zdaniem nie warto.
INFO:wyoming_faster_whisper.handler: wywąc lampkę biurka
Tyle tu skrótów myślowych i niedopowiedzeń (jak dla mnie osoby technicznej), że Twoja opinia może nie być brana pod uwagę. Jeżeli coś porównujemy/testujemy to należy podzielić sie wszystkimi szczegółami technicznymi.
Trochę odkopuję wątek, gdyż także miałem zamiar zakupić M5Stack Atom Echo do sterowania głosem lokalnie. Niestety jak czytam Wasze opinie to mam spore wątpliwości.
Jednakże osobiście mam obawy czy te Wasze błędnie interpretowane komendy nie wynikają właśnie z wyboru języka polskiego. W końcu jest znacznie trudniejszy w interpretacji niż język angielski i w dodatku na głośnikach również wydajemy polecenia po angielsku.
Według mnie to akurat całkowicie naturalne pytanie. Nikt przecież nie zagłębia się w detale, tylko porównuje pod względem praktycznym tzn, czy dobrze reaguje na głos i jak radzi sobie z rozpoznawaniem mowy.
Cześć,
To ja mam pytanie związane z samym połączeniem urządzenia do sieci wifi.
Router TPLink AX3000, szyfrowanie WPA2-PSK[AES] - prócz tego szyfrowania w WPA2 ma jeszcze tylko w wersji Enterprise oraz juz WPA3
Atom za nic nie chce się połączyć z wifi.
Ma ktoś jakiś pomysł na to?
najlepiej wrzuć skrinszota co tam masz dostępne w interfejsie konfiguracyjnym
- Wyłącz WPA3 (ma być WPA/WPA2 personal)
- Wyłącz AX = zrzuć pasmo 2.4GHz do pracy w AC lub N - prawdopodobnie dostępna opcja to B,G,N
- Ustaw hasło tylko ze “zdrowych znaków” (anglojęzyczne litery i cyfry)
- Szerokość kanału 20MHz
- Wybierz jakikolwiek statyczny kanał (zalecane 1, 6 lub 11)
emulator tego modelu symuluje jakieś archaiczne firmware
(ten model jest w ogóle dopuszczony do sprzedaży w Europie?)
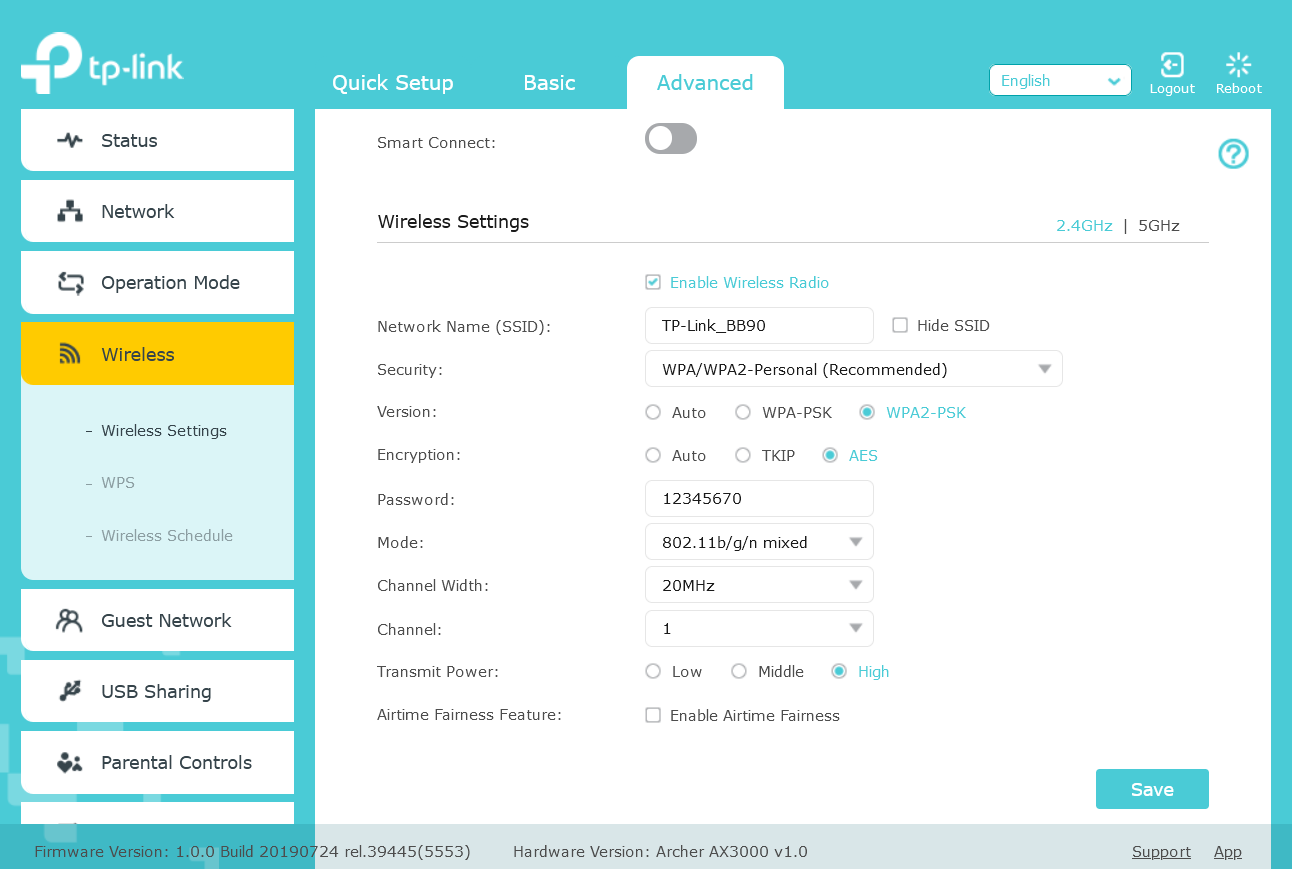
na ustawieniach jak z obrazka nie powinno być problemu z połączeniem
Cześć,
Trochę odkopię temat ale może nie wszyscy użytkownicy Atom Echo wiedzą, że pojawił się tryb ciągłej konwersacji (wersja firmware 25.6.1), który ZNAKOMICIE polepsza działanie asystenta. W dodatku namierzyłem świetną modyfikację poprzedniej wersji yaml w tym wątku, dzięki której urządzenie asystenta dostaje kilka nowych właściwości w HA, przede wszystkim możliwość przekierowania głosu do zewnętrznego, określonego przez użytkownika, odtwarzacza mediów! Udało mi się zaaplikować te zmiany do wersji z ciągłą konwersacją i działa to SUPER! ![]() Dla zainteresowanych yaml:
Dla zainteresowanych yaml:
substitutions:
name: atom-echo-sypialnia
friendly_name: Atom Echo sypialnia
esphome:
name: ${name}
name_add_mac_suffix: false
friendly_name: ${friendly_name}
min_version: 2025.5.0
esp32:
board: m5stack-atom
cpu_frequency: 240MHz
framework:
type: esp-idf
logger:
api:
encryption:
key: "your key"
ota:
- platform: esphome
password: "your password"
id: ota_esphome
wifi:
ssid: !secret wifi_ssid
password: !secret wifi_password
ap:
ssid: "Atom-Echo-Sypialnia"
password: "your password"
captive_portal:
button:
- platform: factory_reset
id: factory_reset_btn
name: Factory reset
i2s_audio:
- id: i2s_audio_bus
i2s_lrclk_pin: GPIO33
i2s_bclk_pin: GPIO19
microphone:
- platform: i2s_audio
id: echo_microphone
i2s_din_pin: GPIO23
adc_type: external
pdm: true
sample_rate: 16000
correct_dc_offset: true
speaker:
- platform: i2s_audio
id: echo_speaker
i2s_dout_pin: GPIO22
dac_type: external
bits_per_sample: 16bit
sample_rate: 16000
channel: stereo # The Echo has poor playback audio quality when using mon audio
buffer_duration: 60ms
media_player:
- platform: speaker
name: None
id: echo_media_player
announcement_pipeline:
speaker: echo_speaker
format: WAV
codec_support_enabled: false
buffer_size: 6000
files:
- id: timer_finished_wave_file
file: https://github.com/esphome/wake-word-voice-assistants/raw/main/sounds/timer_finished.wav
on_announcement:
- if:
condition:
- microphone.is_capturing:
then:
- script.execute: stop_wake_word
- light.turn_on:
id: led
blue: 100%
red: 0%
green: 0%
brightness: 100%
effect: none
on_idle:
- script.execute: start_wake_word
- script.execute: reset_led
voice_assistant:
id: va
micro_wake_word:
microphone:
microphone: echo_microphone
channels: 0
gain_factor: 4
media_player: echo_media_player
noise_suppression_level: 2
auto_gain: 31dBFS
on_listening:
- light.turn_on:
id: led
blue: 100%
red: 0%
green: 0%
effect: "Slow Pulse"
on_stt_vad_end:
- light.turn_on:
id: led
blue: 100%
red: 0%
green: 0%
effect: "Fast Pulse"
on_tts_start:
- if:
condition:
switch.is_on: call_script_message
then:
- logger.log: "calling script with message (instead of playing directly to media player)"
- homeassistant.service:
service: !lambda 'return id(script_id).state.c_str();'
data:
message: !lambda 'return x;'
else:
- if:
condition:
switch.is_on: use_remote_media_player
then:
- logger.log: "using remote media player"
- speaker.volume_set: 10%
- homeassistant.service:
service: tts.cloud_say
data:
entity_id: !lambda 'return id(media_player_entity_id).state.c_str();'
message: !lambda 'return x;'
else:
- logger.log: "using internal speaker"
- speaker.volume_set: 100%
- light.turn_on:
id: led
blue: 100%
red: 0%
green: 0%
brightness: 100%
effect: none
on_end:
# Handle the "nevermind" case where there is no announcement
- wait_until:
condition:
- media_player.is_announcing:
timeout: 0.5s
# Restart only mWW if enabled; streaming wake words automatically restart
- if:
condition:
- lambda: return id(wake_word_engine_location).state == "On device";
then:
- wait_until:
- and:
- not:
voice_assistant.is_running:
- not:
speaker.is_playing:
- lambda: id(va).set_use_wake_word(false);
- micro_wake_word.start:
- script.execute: reset_led
on_error:
- light.turn_on:
id: led
red: 100%
green: 0%
blue: 0%
brightness: 100%
effect: none
- delay: 2s
- script.execute: reset_led
on_client_connected:
- delay: 2s # Give the api server time to settle
- script.execute: start_wake_word
on_client_disconnected:
- script.execute: stop_wake_word
on_timer_finished:
- script.execute: stop_wake_word
- wait_until:
not:
microphone.is_capturing:
- speaker.volume_set: 100%
- switch.turn_on: timer_ringing
- light.turn_on:
id: led
red: 0%
green: 100%
blue: 0%
brightness: 100%
effect: "Fast Pulse"
- if:
condition:
switch.is_on: call_alarm_script
then:
- logger.log: "calling alarm script"
- homeassistant.service:
service: !lambda 'return id(alarm_script_id).state.c_str();'
- wait_until:
- switch.is_off: timer_ringing
- light.turn_off: led
- switch.turn_off: timer_ringing
- speaker.volume_set: 10%
binary_sensor:
# button does the following:
# short click - stop a timer
# if no timer then restart either microwakeword or voice assistant continuous
- platform: gpio
pin:
number: GPIO39
inverted: true
name: Button
disabled_by_default: true
entity_category: diagnostic
id: echo_button
on_multi_click:
- timing:
- ON for at least 50ms
- OFF for at least 50ms
then:
- logger.log: "single button short click"
- if:
condition:
switch.is_on: timer_ringing
then:
- switch.turn_off: timer_ringing
else:
- script.execute: start_wake_word
- timing:
- ON for at least 10s
then:
- logger.log: "single button long click"
- button.press: factory_reset_btn
light:
- platform: esp32_rmt_led_strip
id: led
name: None
disabled_by_default: true
entity_category: config
pin: GPIO27
default_transition_length: 0s
chipset: SK6812
num_leds: 1
rgb_order: grb
effects:
- pulse:
name: "Slow Pulse"
transition_length: 250ms
update_interval: 250ms
min_brightness: 50%
max_brightness: 100%
- pulse:
name: "Fast Pulse"
transition_length: 100ms
update_interval: 100ms
min_brightness: 50%
max_brightness: 100%
script:
- id: reset_led
then:
- if:
condition:
- lambda: return id(wake_word_engine_location).state == "On device";
- switch.is_on: use_listen_light
then:
- light.turn_on:
id: led
red: 100%
green: 89%
blue: 71%
brightness: 60%
effect: none
else:
- if:
condition:
- lambda: return id(wake_word_engine_location).state != "On device";
- switch.is_on: use_listen_light
then:
- light.turn_on:
id: led
red: 0%
green: 100%
blue: 100%
brightness: 60%
effect: none
else:
- light.turn_off: led
- id: start_wake_word
then:
- if:
condition:
and:
- not:
- voice_assistant.is_running:
- lambda: return id(wake_word_engine_location).state == "On device";
then:
- lambda: id(va).set_use_wake_word(false);
- micro_wake_word.start:
- if:
condition:
and:
- not:
- voice_assistant.is_running:
- lambda: return id(wake_word_engine_location).state == "In Home Assistant";
then:
- lambda: id(va).set_use_wake_word(true);
- voice_assistant.start_continuous:
- id: stop_wake_word
then:
- if:
condition:
lambda: return id(wake_word_engine_location).state == "In Home Assistant";
then:
- lambda: id(va).set_use_wake_word(false);
- voice_assistant.stop:
- if:
condition:
lambda: return id(wake_word_engine_location).state == "On device";
then:
- micro_wake_word.stop:
switch:
- platform: template
name: Use listen light
id: use_listen_light
optimistic: true
restore_mode: RESTORE_DEFAULT_ON
entity_category: config
on_turn_on:
- script.execute: reset_led
on_turn_off:
- script.execute: reset_led
- platform: template
name: Use remote media player
id: use_remote_media_player
optimistic: true
restore_mode: RESTORE_DEFAULT_ON
entity_category: config
on_turn_on:
- logger.log: "use remote media player turned on"
- logger.log:
format: "current media player entity: %s"
args: ["id(media_player_entity_id).state.c_str()"]
on_turn_off:
- logger.log: "use remote media player turned off"
- logger.log:
format: "current media player entity: %s"
args: ["id(media_player_entity_id).state.c_str()"]
- platform: template
name: Call script with message
id: call_script_message
optimistic: true
restore_mode: RESTORE_DEFAULT_ON
entity_category: config
on_turn_on:
- logger.log: "call script with message turned on"
on_turn_off:
- logger.log: "call script with message turned off"
- platform: template
name: Call alarm script
id: call_alarm_script
optimistic: true
restore_mode: RESTORE_DEFAULT_ON
entity_category: config
on_turn_on:
- logger.log: "call alarm script turned on"
on_turn_off:
- logger.log: "call alarm script turned off"
- platform: template
id: timer_ringing
optimistic: true
restore_mode: ALWAYS_OFF
on_turn_off:
# Turn off the repeat mode and disable the pause between playlist items
- lambda: |-
id(echo_media_player)
->make_call()
.set_command(media_player::MediaPlayerCommand::MEDIA_PLAYER_COMMAND_REPEAT_OFF)
.set_announcement(true)
.perform();
id(echo_media_player)->set_playlist_delay_ms(speaker::AudioPipelineType::ANNOUNCEMENT, 0);
# Stop playing the alarm
- media_player.stop:
announcement: true
on_turn_on:
# Turn on the repeat mode and pause for 1000 ms between playlist items/repeats
- lambda: |-
id(echo_media_player)
->make_call()
.set_command(media_player::MediaPlayerCommand::MEDIA_PLAYER_COMMAND_REPEAT_ONE)
.set_announcement(true)
.perform();
id(echo_media_player)->set_playlist_delay_ms(speaker::AudioPipelineType::ANNOUNCEMENT, 1000);
- media_player.speaker.play_on_device_media_file:
media_file: timer_finished_wave_file
announcement: true
- delay: 15min
- switch.turn_off: timer_ringing
text:
- platform: template
name: Media Player Entity ID
id: media_player_entity_id
mode: text
optimistic: true
restore_value: true
entity_category: config
on_value:
then:
- logger.log:
format: "Set new media player entity: %s"
args: ["x.c_str()"]
- platform: template
name: Script ID
id: script_id
mode: text
optimistic: true
restore_value: true
entity_category: config
on_value:
then:
- logger.log:
format: "Set new script: %s"
args: ["x.c_str()"]
- platform: template
name: Script on Alarm ID
id: alarm_script_id
mode: text
optimistic: true
restore_value: true
entity_category: config
on_value:
then:
- logger.log:
format: "Set new alarm script: %s"
args: ["x.c_str()"]
select:
- platform: template
entity_category: config
name: Wake word engine location
id: wake_word_engine_location
optimistic: true
restore_value: true
options:
- In Home Assistant
- On device
initial_option: On device
on_value:
- if:
condition:
lambda: return x == "In Home Assistant";
then:
- micro_wake_word.stop:
- delay: 500ms
- lambda: id(va).set_use_wake_word(true);
- voice_assistant.start_continuous:
- if:
condition:
lambda: return x == "On device";
then:
- lambda: id(va).set_use_wake_word(false);
- voice_assistant.stop:
- delay: 500ms
- micro_wake_word.start:
micro_wake_word:
on_wake_word_detected:
- voice_assistant.start:
wake_word: !lambda return wake_word;
vad:
models:
- model: okay_nabu
- model: hey_mycroft
- model: hey_jarvis
W tym momencie mam dwa super działające echa. Jedno jest na stałe przekierowane do zewnętrznego głośnika via VLC w HA a drugie do głośników komputera z Windowsami via HASS.Agent, przy czym przekierowanie się wyłącza w momencie zamknięcia windowsów i automatyzacja skierowuje dźwięk asystenta z powrotem na głośniczek echa. Mam nadzieję, że się komuś te informacje przydadzą ![]()
EDIT: byłbym zapomniał. Aby tryb ciągłej konwersacji działał AI musi kończyć wypowiedź znakiem zapytania. W tym celu do propmta trzeba dodać takie coś: “If you are expecting a follow up response, always put a question at the end of the last sentence.”
2 polubienia