Od kilku dni supervisor mojej instancji HA ma jakiś problem z autentykacją:
23-02-03 18:08:44 ERROR (MainThread) [supervisor.api.middleware.security] Invalid token for access /supervisor/info
23-02-03 18:08:44 ERROR (MainThread) [supervisor.api.middleware.security] Invalid token for access /supervisor/info
Nie mam pojęcia jak mu pomóc…
Ponadto doznałem totalnego zaskoczenia, takiego z kategorii szoków lekko wstrząsających widząc to, co poniżej. Zobaczcie sami:
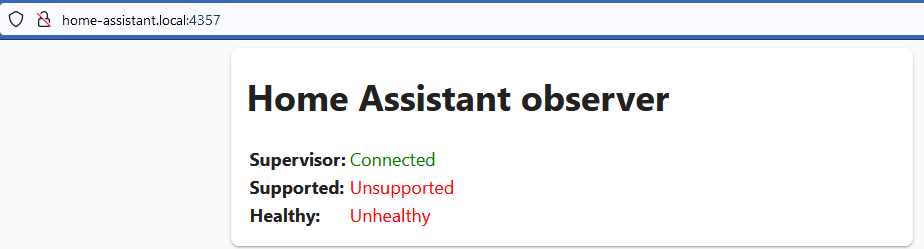
Na ekranie UI superwisiora widzę takie coś:
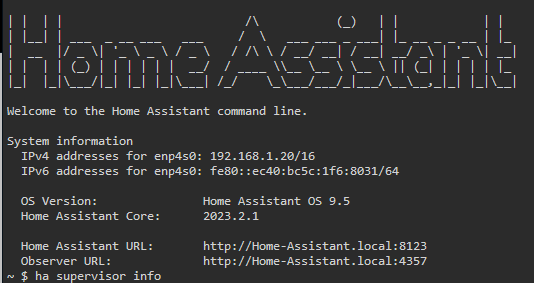
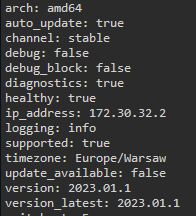
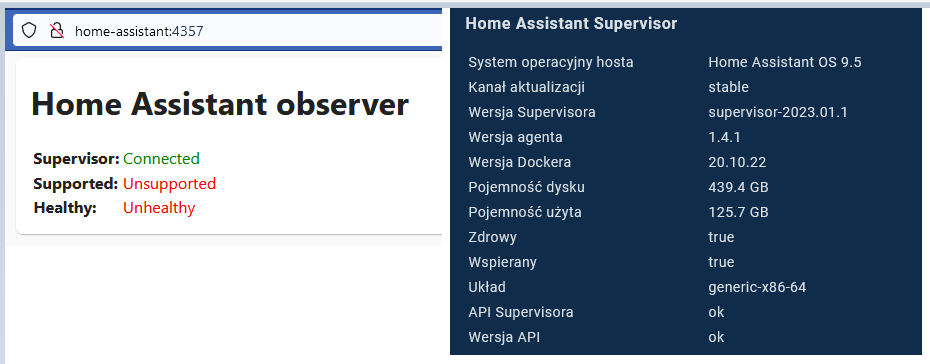
Tymczasem terminal tej samej maszynki pokazuje, że:
Na pierwszym ekranie widzę, że superwisior zachorował (nie wiem na co) i nie jest supportowany, ale okno terminala usiłuje mi wzmówić coś całkiem przeciwnego. Popatrzcie sami.
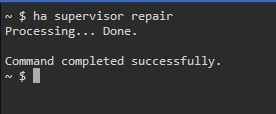
Komu wierzyć? Dlaczego komunikaty się wykluczają? Jak skutecznie przywrócić superwisiora do zdrowia? Czy on w ogóle jest chory? Polecenie z konsoli ha supervisor repair wykonuje jakiś dziwnie podejrzany, kilkuminutowy proces ‘naprawczy’ (nie wyświetla jakie błędy znalazł), po czym odbtrąbia sukces, i tyle. Nie widać co naprawił i czy w ogóle było co naprawiać:
Co więcej, po takiej naprawie na ekranie superwisiora nadal widać ostrzeżenie o jego niezdrowej kondycji.
Czy mógłbym Was prosić o wytłumaczenie tego stanu rzeczy?
Być może jest na to jakieś racjonalne wytłumaczenie ale moja wiedza w tym zakresie sięga dna…
PS: Nie wiem, czy to właściwy dział Forum, ale nie znalazłem lepszego…
Zawsze w przypadku błędnego działania GUI można wcisnąć ctrl+F5 i/lub wyczyścić cache przeglądarki.
Nie wiem wprawdzie czy Observer podlega cache’owaniu, ale widywałem już różne rozwiązania.
Oczywiście cache czyszczę regularnie przed i po zabiegu reanimacji… Za każdym razem dostaję te same wyniki, przeciwstawne co do treści w zależności od źródła, z których pochodzą.
3 kropeczki otwierają okno z następującą informacją:
## System Information
version | core-2023.2.1
-- | --
installation_type | Home Assistant OS
dev | false
hassio | true
docker | true
user | root
virtualenv | false
python_version | 3.10.7
os_name | Linux
os_version | 5.15.90
arch | x86_64
timezone | Europe/Warsaw
config_dir | /config
Home Assistant Community Store
GitHub API | ok
-- | --
GitHub Content | ok
GitHub Web | ok
GitHub API Calls Remaining | 5000
Installed Version | 1.30.1
Stage | running
Available Repositories | 1263
Downloaded Repositories | 50
HACS Data | ok
Home Assistant Supervisor
host_os | Home Assistant OS 9.5
-- | --
update_channel | stable
supervisor_version | supervisor-2023.01.1
agent_version | 1.4.1
docker_version | 20.10.22
disk_total | 439.4 GB
disk_used | 125.7 GB
healthy | true
supported | true
board | generic-x86-64
supervisor_api | ok
version_api | ok
installed_addons | Home Assistant Google Drive Backup (0.110.1), Mosquitto broker (6.1.3), SSH & Web Terminal (13.0.2), Studio Code Server (5.5.2), Zigbee2MQTT (1.30.0-1), Duck DNS (1.15.0), ZeroTier One (0.16.0), HoyMiles Solar Gateway Addon (1.0.7), Samba share (10.0.0), NGINX Home Assistant SSL proxy (3.2.0), ESPHome (2022.12.8), Vaultwarden (Bitwarden) (0.19.0), AppDaemon (0.11.0), SQLite Web (3.7.0), Node-RED (14.0.2)
Dashboards
dashboards | 2
-- | --
resources | 35
views | 27
mode | storage
Recorder
oldest_recorder_run | 14 stycznia 2023 06:29
-- | --
current_recorder_run | 3 lutego 2023 21:10
estimated_db_size | 1518.53 MiB
database_engine | sqlite
database_version | 3.38.5
Nie mam problemów z qumaniem j. ang. i z raczej dobrze rozumiem treść powyższego ekranu w sekcji superwisiora:
healthy | true
supported | true
board | generic-x86-64
supervisor_api | ok
version_api | ok
Całość zakończona jest następującą sekcją:
@artpc , to, co piszesz nie zbliża mnie do odpowiedzi na zasadnicze, tytułowe pytanie: czy mój SV jest chory, czy zdrowy? Któremu ekranowi wierzyć i dlaczego?
Stawiam na to po lewej (że “kłamie”).
Pytanie za 3 punkty
to po prawej masz pod http://home-assistant:8123?
ciekaw jestem czy faktycznie adres masz w tej samej postaci, czy to jakiś obrazek z cache bo u mnie wygląda inaczej (animowane tło i inne pierdoły).
Adres okna z lewej: http://home-assistant:4357
Adres okna z prawej: https://xxxx.duckdns.org/config/repairs
Na routerze taki oto wpis w celu uzyskania wjazdu do HA spoza sieci domowej:
Wciąż próbuję zwalczyć “chorobę” mojego supervisora… Przeglądając jego logi nie trafiam, na żaden błąd krytyczny, poza jednym, który powtarza się dość regularnie:
Czy oznacza to, że token wygasł? Czy powinienem wygenerować nowy token? Jak to zrobić? Jak powiązać wygenerowany token z supervisorem (bo rozumiem, że wygenerowany token dedykowany bedzie tylko dla supervisora)…
Po wykonaniu ha core rebuild oraz ha su repair pojawiły się kolejne błędy:
23-02-09 19:26:12 INFO (MainThread) [supervisor.homeassistant.api] Updated Home Assistant API token
23-02-09 19:26:12 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API request initialize
23-02-09 19:26:13 INFO (MainThread) [supervisor.api.proxy] WebSocket access from a0d7b954_nodered
23-02-09 19:26:13 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API request running
23-02-09 19:26:31 INFO (MainThread) [supervisor.auth] Auth request from 'core_mosquitto' for 'mqtt'
23-02-09 19:27:01 ERROR (MainThread) [supervisor.homeassistant.api] Error on call https://172.30.32.1:8123/api/hassio_auth:
23-02-09 19:27:01 ERROR (MainThread) [supervisor.auth] Can't request auth on Home Assistant!
23-02-09 19:27:01 ERROR (MainThread) [asyncio] Task exception was never retrieved
future: <Task finished name='Task-39095' coro=<Auth._backend_login() done, defined at /usr/src/supervisor/supervisor/auth.py:90> exception=AuthError()>
Traceback (most recent call last):
File "/usr/src/supervisor/supervisor/auth.py", line 116, in _backend_login
raise AuthError()
supervisor.exceptions.AuthError
23-02-09 19:27:26 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API connection is closed
23-02-09 19:27:48 WARNING (MainThread) [supervisor.homeassistant.websocket] Connection is closed
23-02-09 19:28:01 ERROR (MainThread) [supervisor.homeassistant.api] Error on call https://172.30.32.1:8123/api/config:
23-02-09 19:28:04 ERROR (MainThread) [supervisor.homeassistant.api] Error on call https://172.30.32.1:8123/api/config:
23-02-09 19:28:16 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API request initialize
23-02-09 19:28:16 INFO (MainThread) [supervisor.api.proxy] WebSocket access from a0d7b954_nodered
23-02-09 19:28:16 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API request running
23-02-09 19:35:11 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API error: Received message 257:None is not str
23-02-09 19:35:11 INFO (MainThread) [supervisor.api.proxy] Home Assistant WebSocket API connection is closed
23-02-09 19:35:16 WARNING (MainThread) [supervisor.misc.tasks] Watchdog/Application found a problem with observer plugin!
23-02-09 19:35:41 ERROR (MainThread) [supervisor.homeassistant.api] Error on call https://172.30.32.1:8123/api/config:
23-02-09 19:36:08 ERROR (MainThread) [asyncio] Task exception was never retrieved
Najgorszy z nich to chyba ten: 23-02-09 19:27:01 ERROR (MainThread) [supervisor.auth] Can't request auth on Home Assistant!
Nie umiem tego zinterpretować…
Wygląda to tak jakby zmienił się adres w Docker. spróbuj wyłączyć całkowicie HA, odepnij od sieci, zrestartuj router/switch potem w odwrotnie kolejności na końcu HA .
Ja bym zrobił pełny backup na wypadek sytuacji w której się to już nie podniesie, a następnie cofnął wersję systemu ha os update --version 9.4
i sprawdził czy nadal błąd występuje.
Tylko jeśli nastąpi magiczna naprawa, to w 1 kroku jeszcze 2 oczka w dół ( → 9.2), a potem kolejne update po jednym oczku w górę ( → 9.3 → 9.4 → 9.5 to taktyka zmiany slotów systemu).
Ja też o tym myślałem… BackUp robi się u mnie codziennie tym narzędziem ale nie wiem, jak postąpić dalej, aby:
mieć świeży, w pełni sprawny system HA (rozważam nową instalację od zera, ponownie “na goły metal”), i jednocześnie …
…nie stracić efektów swojej rocznej pracy (dashboardy, flowy/subflowy NR, konfiguracje/customizacje encji, automatyzacje, konfigurację integracji Z2M wraz z ponad setką sparowanych i skonfigurowanych już urządzeń).
Liczę się z utratą danych historycznych i innych danych, na których mało mi zależy, ale za żadną cenę nie chciałbym stracić spędzonych nocy i dni nad aktualnym wyglądem lowelasa.
Oj, bardzo przydałby jakiś instruktaż (@artpc, nieśmiało sugeruję może jakiś filmik na YT?) na taką okoliczność, gdy wszelkie miękkie zabiegi zawodzą i pozostaje twardy reinstall z maksymalnym odzyskaniem włożonej dotąd pracy. Ale do tego potrzebna jest gruntowna i szczegółowa wiedza o strukturach plików i folderów HA, aby wiedzieć, co i gdzie jest przechowywane, jakie pliki archiwalne można skopiować do nowej instalacji, a które z nich wymagają tworzenia od zera…
ha core rebuild
ha supervisor repair
ha supervisor update
3.Restar
Można zrestartować kontener, ale nie wiem czy w twoim wierszu poleceń jest to obsługiwane. sudo docker ps -a docker restart 52edf8e460ff ID kontenera supervisor, twój może mieć inne ID
Zrób jednak ręcznie po zatrzymaniu Dodatków (niektóre powodują konflikty i można zostać z ręką w nocniku) i pobierz sobie go na komputer z którego piszesz.
Pełny backup zawiera wszystko oprócz systemu i podstawowej konfiguracji sieci.
Metoda “z dmuchaniem na zimne”, to użycie innego nośnika do świeżej instalacji i przywrócenia backupu na etapie onboardingu, oraz zostawienie oryginalnego, który używasz teraz w nienaruszonym stanie.
Tutorialik dla HAOS-generic jest od dawna, gdybyś miał inny rodzaj instalacji to można go użyć tylko w opisanym zakresie
Pełny backup właśnie zrobiony i wyciągnięty na odrębny komputer. Teraz planuję następujące czynności:
Zaoranie dysku w hoście
Wykonanie świeżej instalacji HA na goły metal
Odtworzenie wszystkich zbackupowanych komponentów (wykonanie RESTORE na etapie onboardingu ze zrobionego przed chwilą pełnego backupu).
Prawdopodobne sparowanie wszystkich urządzeń zigbee od początku (czy tak? A może pełny backup zachował sparowanie? Nie wiem tego.)
Jeśli ten plan jest poprawny, to mam jedną zasadniczą wątpliwość, dotyczącą tego zdania:
Czy wykonanie RESTORE z takiego backupu przypadkiem nie odtworzy z powrotem problemu? Czy odtworzenie komponentów z backupu nie nadpisze problemu na nowej, zdrowej instalacji?
W prawdzie backup to nie jest twardy snapshot z wierną fotografią całego środowiska (zawierającą także źródło mojej awarii), ale wolę zapytać/upewnić się zanim rozpocznę całą akcję.
Tego to oczywiście nie wiem, dlatego sugeruję pozostawienie obecnego nośnika (zapewne ssd) w stanie nienaruszonym a świeżą instalację na innym.
Generalnie backup nie przywraca systemu, wszystko co jest skonfigurowane (łącznie z Z2M) zostaje przywrócone.
Jeśli chcesz sobie przeanalizować co zawiera backup to jeśli masz dostatecznie dużo czasu po prostu do niego zajrzyj - to typowe archiwum tar.gzip więc np. pod Windows 7zip je otwiera.
PS Próbowałeś cofnąć wersję systemu? Zaproponowałem to nie bez powodu - HAOS 9.5 zawiera zmiany dotyczące routingu sieci supervisora.
Niestety, cofnięcie wersji OS do 9.4 nic nie dało. Co więcej, nadal postępuje degradacja HA, następuje coraz częstsza utrata połączenia (dostępu do hosta), wielogodzinne zwisy:
które często muszę przywracać twardym rebootem serwera, bo inaczej HA w ogóle nie chce się odezwać. O dziwo, ping do IP serwera HA działa cały czas bez zakłóceń… Wnioskuję z tego, że sama sieć działa w zasadzie poprawnie, ale konfiguracja trzymana w HA jest zasadniczo błędna…
Niestety, nie mam żadnego wolnego SSD na podmianę, więc chyba nie pozostaje mi nic innego jak postawienie nowej instalacji na tym samym nośniku i odtworzenie zawartości wykonanego wcześniej backupu…
Zaglądałem do ZIP’a, widzę wszystkie zbackupowane pliki, nie wiem tylko czy mogę dowolnie (wybiórczo) wyciągać stąd pliki i bezkarnie podmieniać je w nowej instalacji.