taka ciekawostka mnie dziś złapała…
ktoś coś podpowie gdzie szukać problemu?
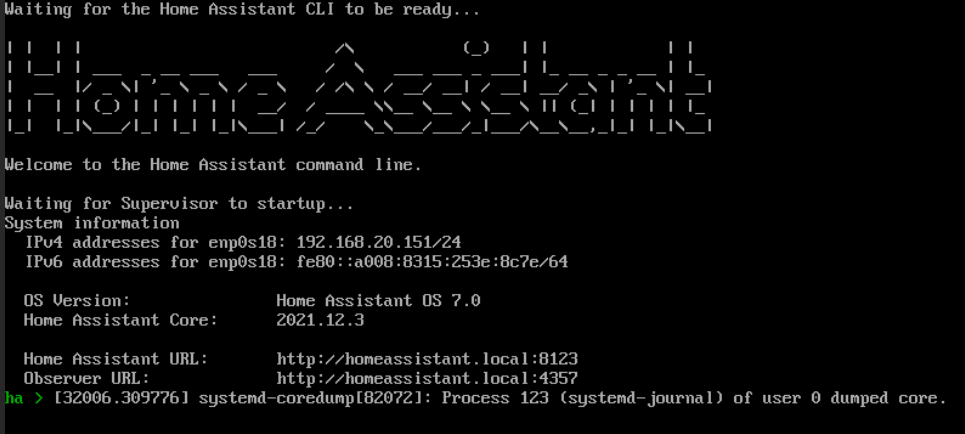
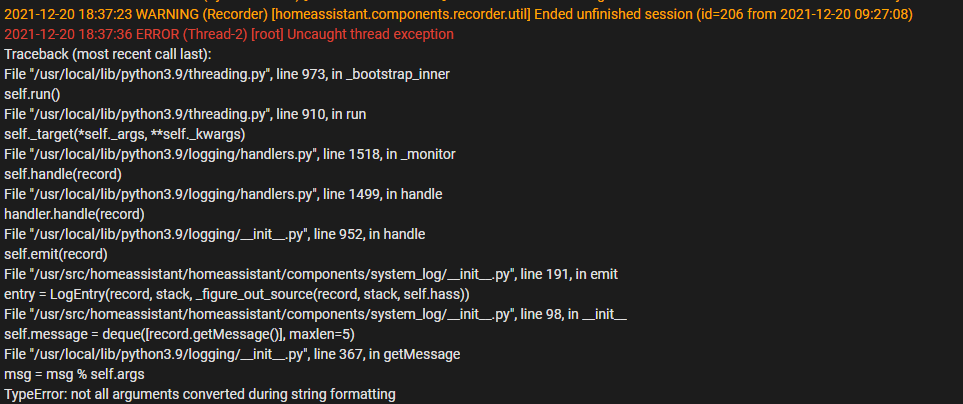
HA najnowszy postawiony na Proxmoxie i tyle z konsoli widzę, po restarcie z Proxmoxa wstaje wszystko… to już któryś raz więc trzeba znaleźć przyczynę
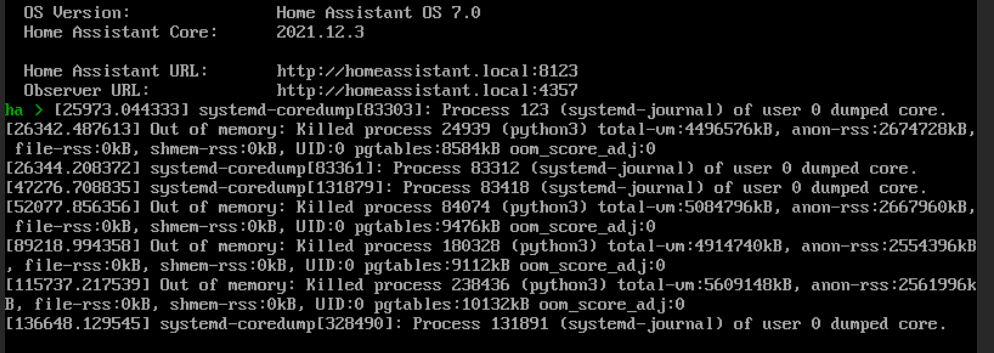
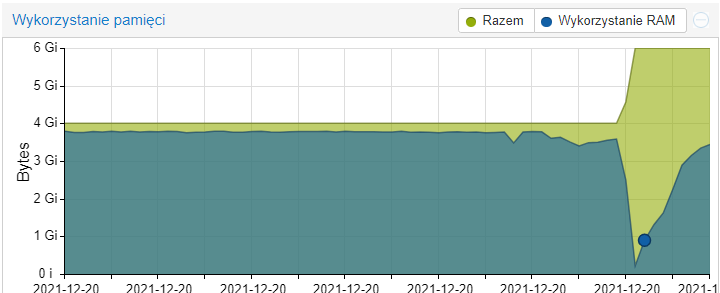
tylko że mój komputer ma 10GB wbudowanej pamięci RAM a na HA przeznaczyłem 4GB więc to nie problem samego komputera tylko czegoś co w HA zabrało całą tą pamięć…
a czy idzie jakąś komendą sprawdzić co ile zabiera ? bo powiększyć mogę przydzielenie pamięci - ale czy to nie będzie zabieg na chwilę skoro dotychczas działało?
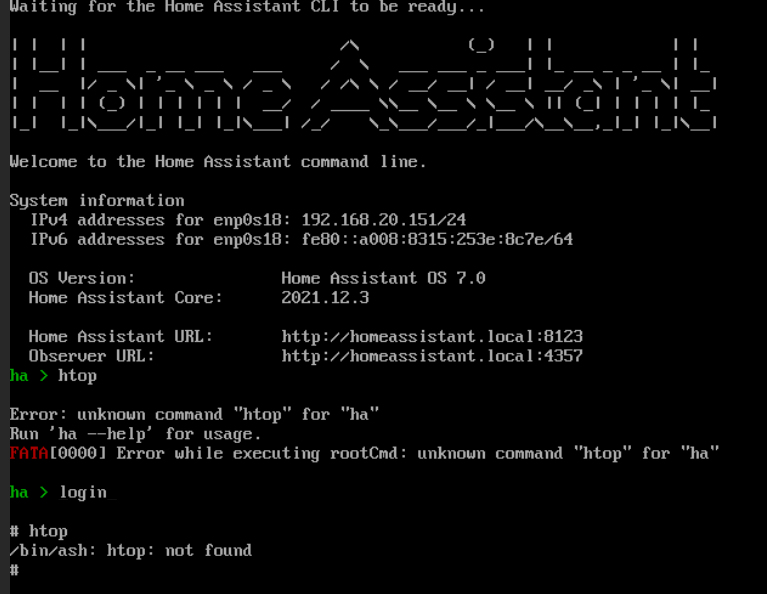
Nie w CLI (tu jesteś wewnątrz programu HA), tylko w terminalu (doinstaluj sobie jakiś jako addon, lepiej ten alternatywny w “sklepie” z grupy Community).
Ponadto możesz doinstalować sobie addon Glances.
PS Jeśli by nie było htop to na 100% jest przynajmniej top (nie mam dostępu do CLI, więc nie sprawdzę)…
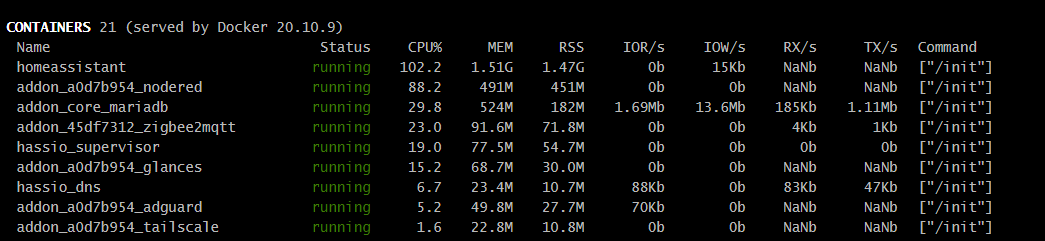
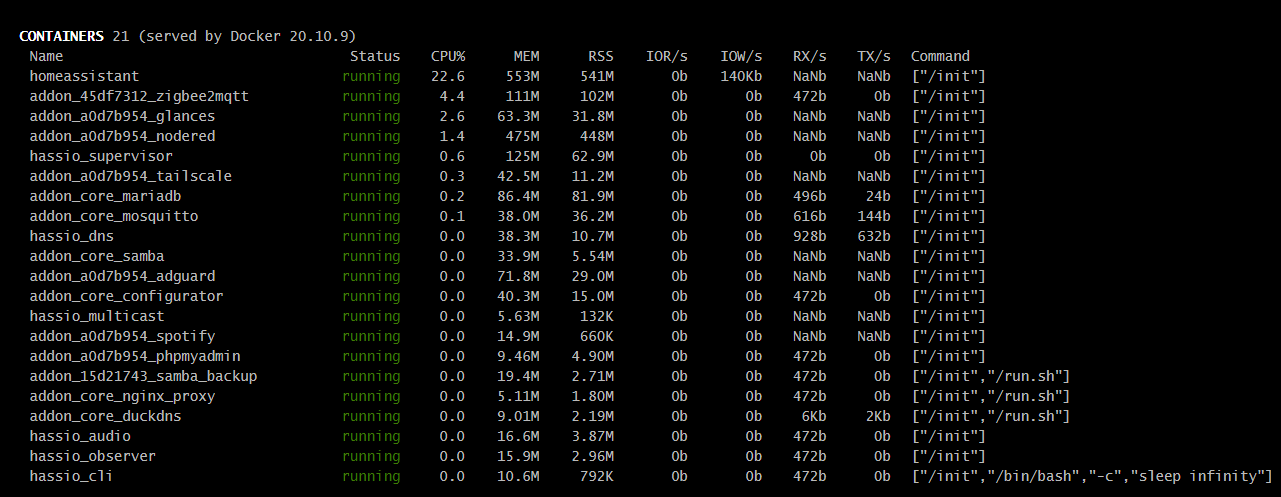
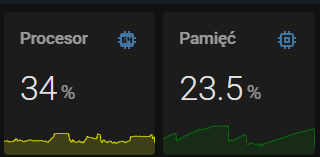
Kiedyś miałem glances ale sam w sobie zjadał dużo zasobów więc usunąłem - teraz wrzuciłem na sprawdzenie i niepokoi mnie trochę to zużycie…
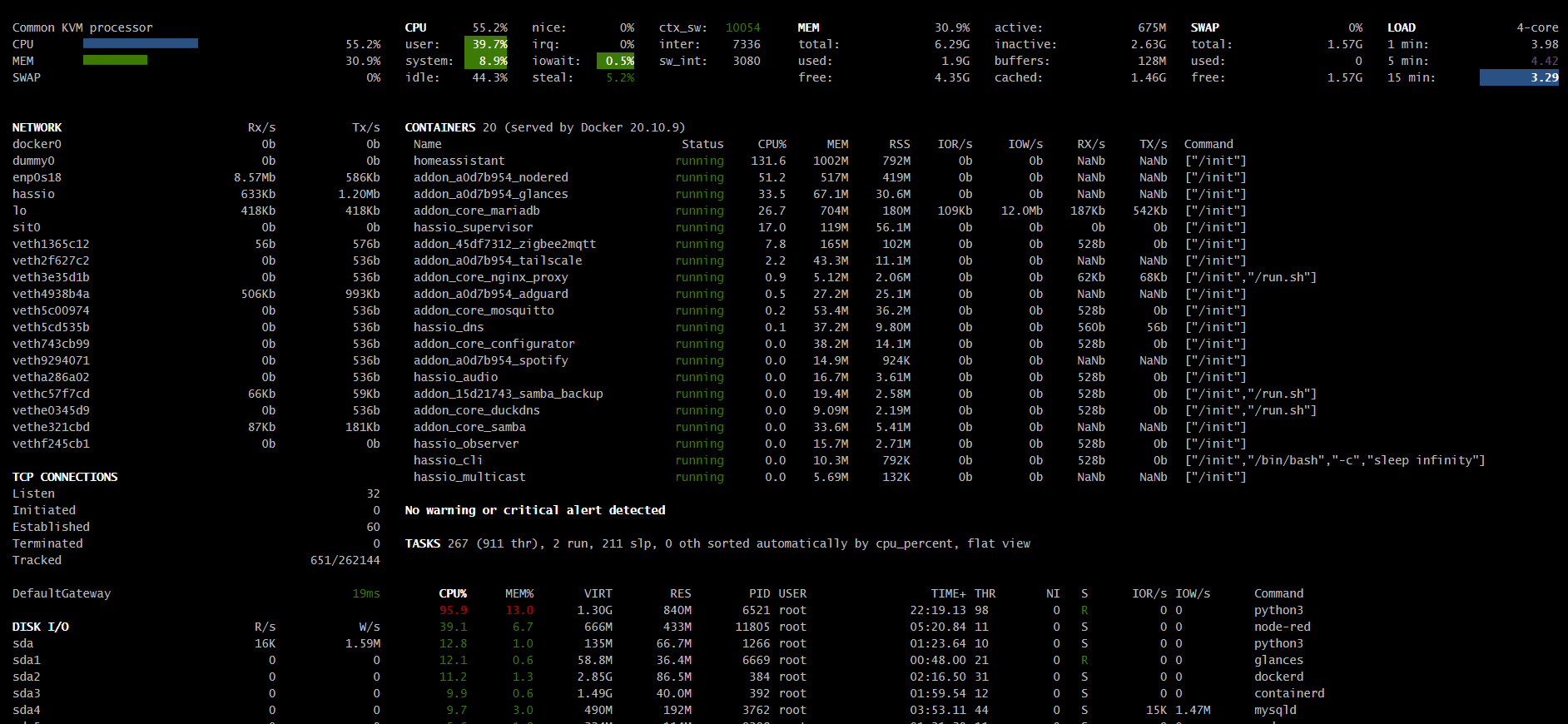
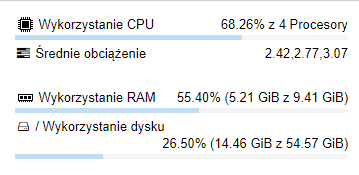
kiedyś czytałem że ponad 100% to nie problem ponieważ tutaj są 4 rdzenie więc dzielimy /4 … ale to chyba i tak trochę za dużo ?
Tylko wyświetlenie jego interfejsu zjada te zasoby, gdy pracuje w tle i korzystasz z jego sensorów nie ma tragedii, a skoro system się wywraca z braku pamięci, to chyba warto poznać przyczynę.
Load (ten który powinien być w prawym górnym rogu) dzielimy przez ilość rdzeni (w VM udostępnionych rdzeni), obciążenie w % dotyczy całego dostępnego procesora (tego kawałka, który przydzieliłeś dla VM).
Więc jeśli masz ponad 100% to albo za mało procka przydzieliłeś do VM albo dzieją się bardzo złe rzeczy - system już nie pracuje w czasie rzeczywistym.
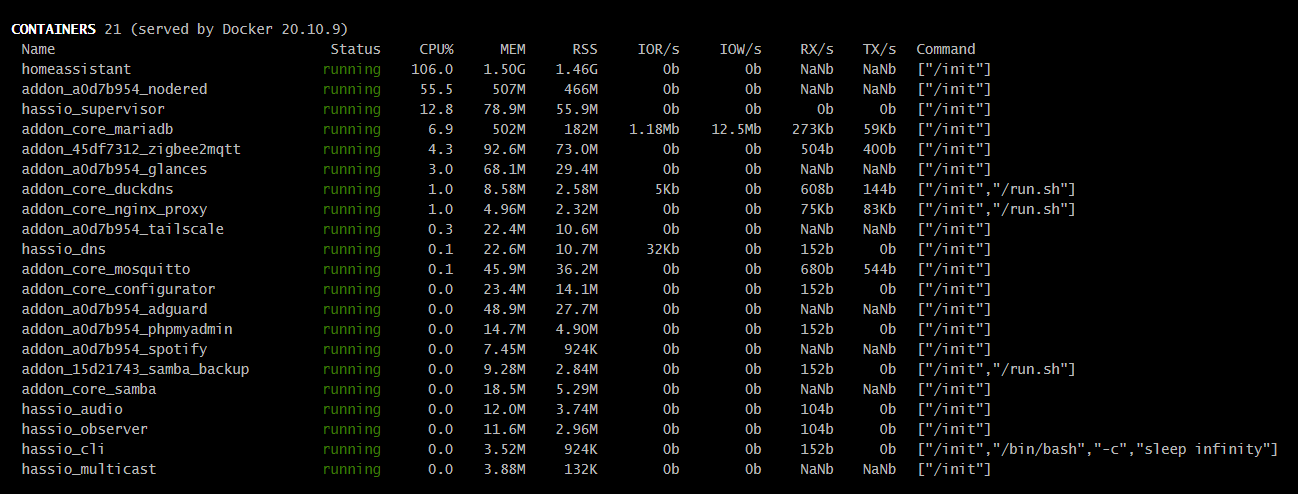
będę musiał testować i po kolei wyłączać aby sprawdzić to zjada… ponieważ parametry samej HA są OK. w zasadzie Fujitsu Futro S920 ma 4rdzenie i 10gb więc spora część jest przeznaczona na HA, możliwe że po prostu za dużo tego wszystkiego już jest oparte na HA i trzeba szukać jeszcze mocniejszego sprzętu pod takie wymagania.
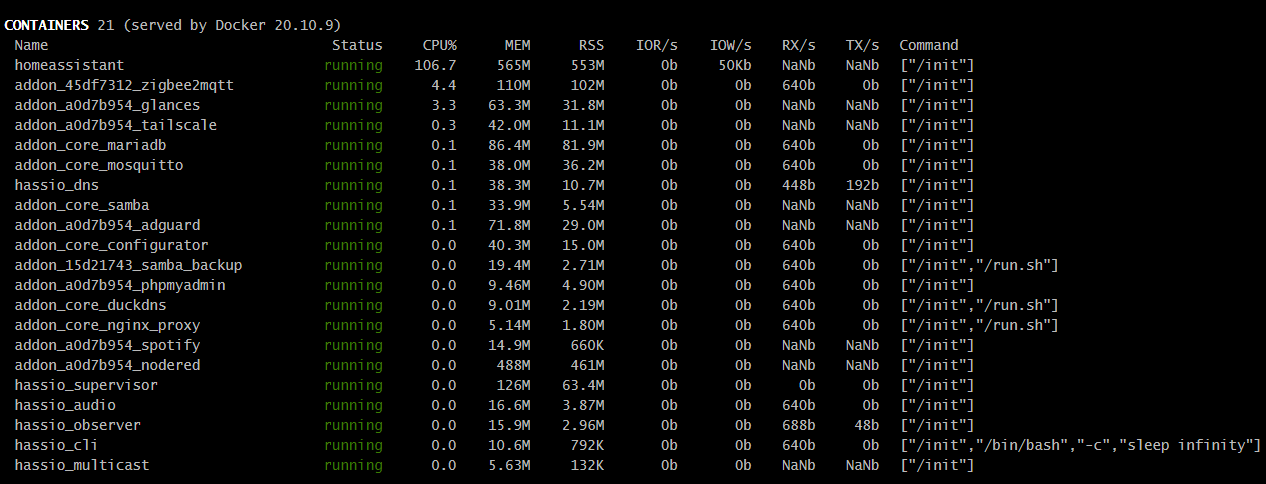
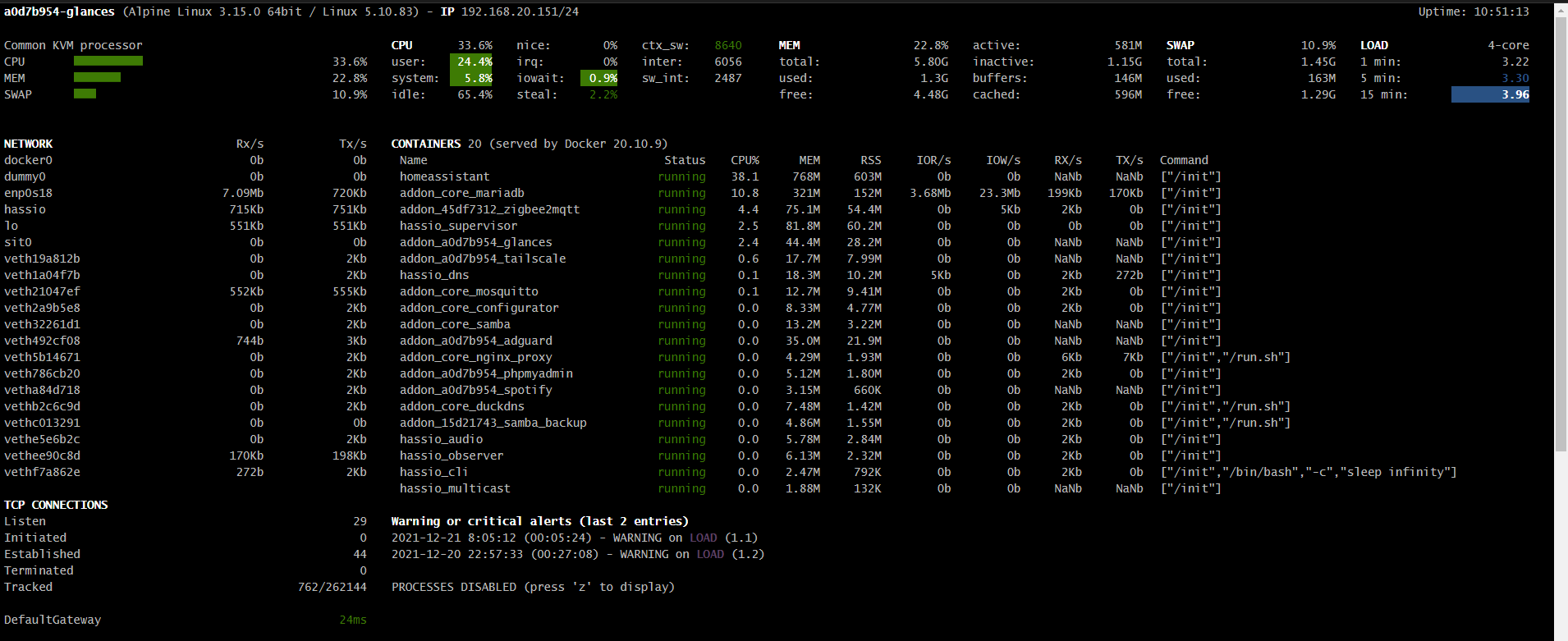
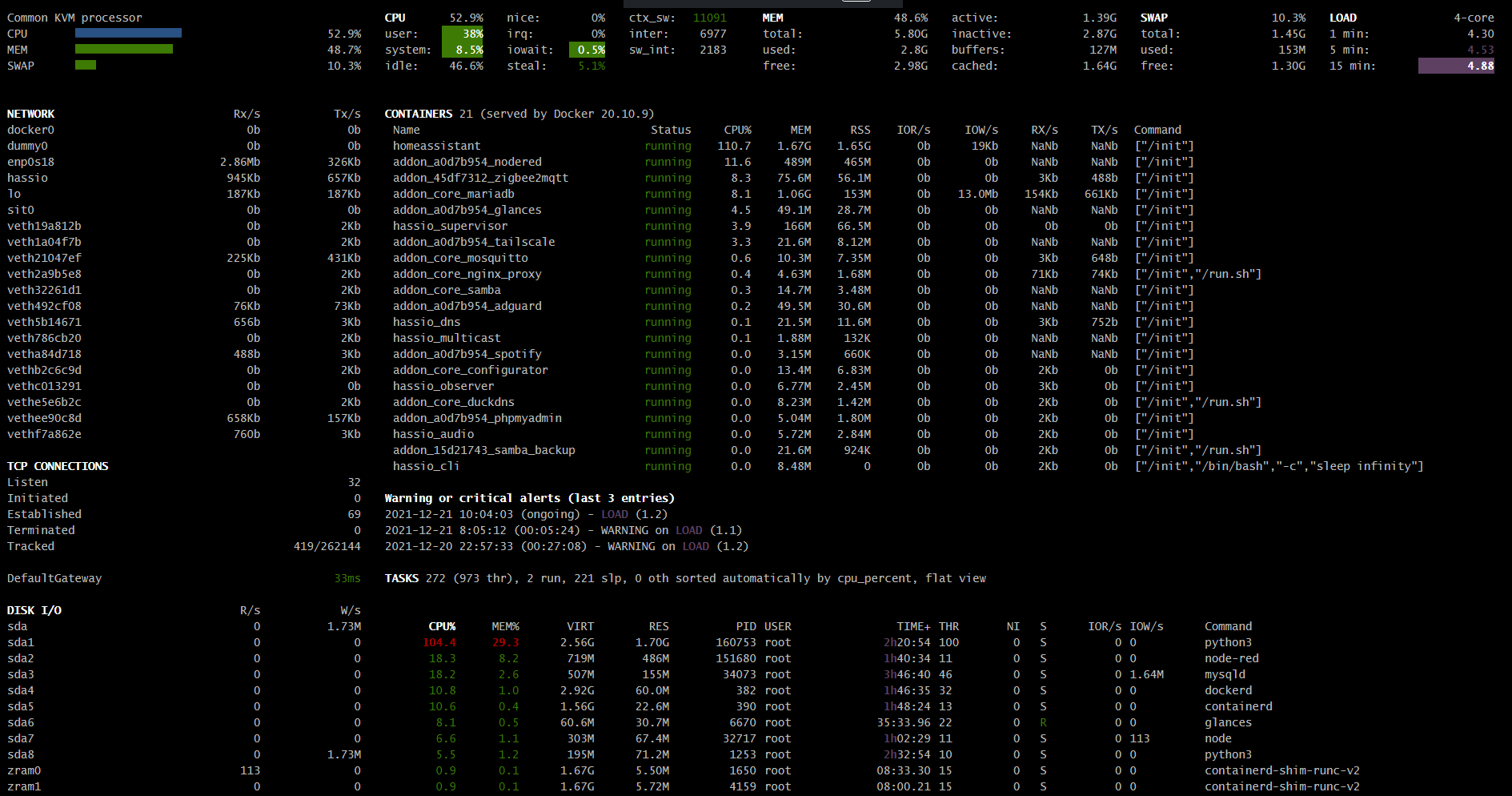
Wprowadziłem nieco zamieszania “CPU%” w kontenerach i procesach jest w przeliczeniu na rdzenie (podobnie jak “Load” w podsumowaniu), natomiast na twoich screenshotach brakuje góry gdzie powinno być widać całkowite obciążenie CPU (tego o którym wspomniałem wyżej - lewo u góry) oraz parę innych parametrów po których z grubsza można ocenić co się dzieje (np. wykorzystanie swap)
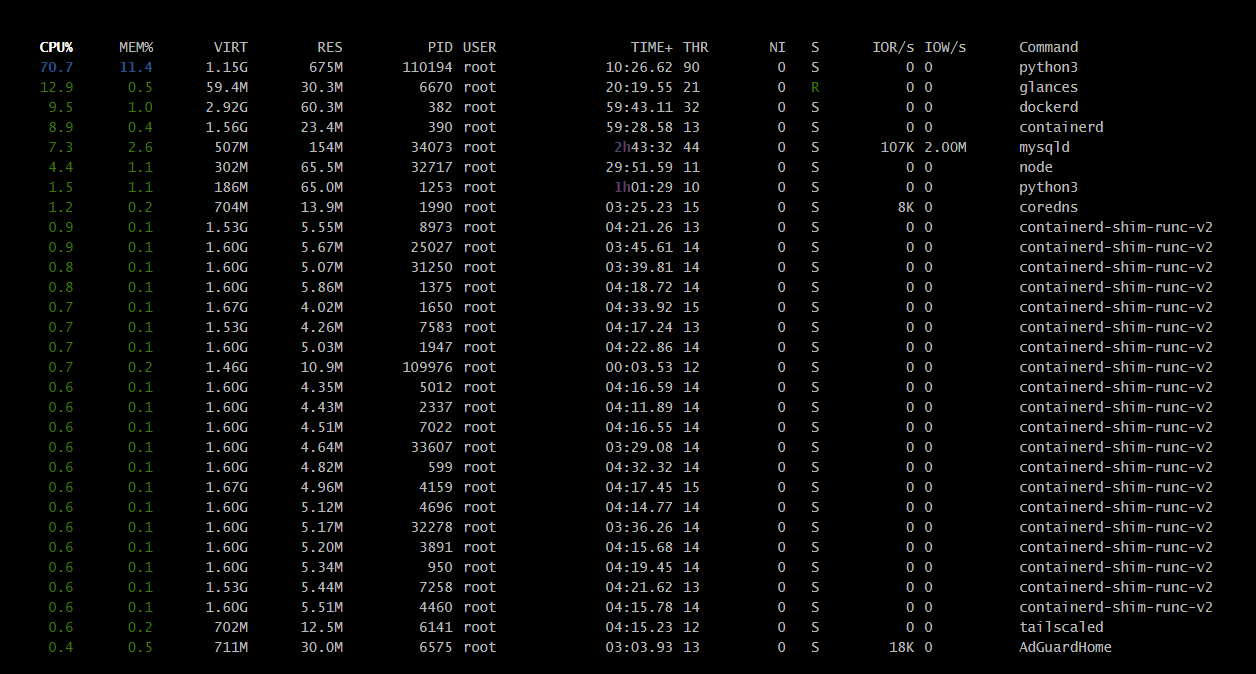
Swoją drogą można przełączać wygląd Glances, w tym można sobie wyświetlić obciążenie globalne per CPU (czyli na rdzenie), ale raczej najciekawszy jest sektor na dole (po wciśnięciu z) gdzie są wylistowane procesy, a sortowanie jest możliwe w/g różnych parametrów (skróty klawiaturowe są pod h)
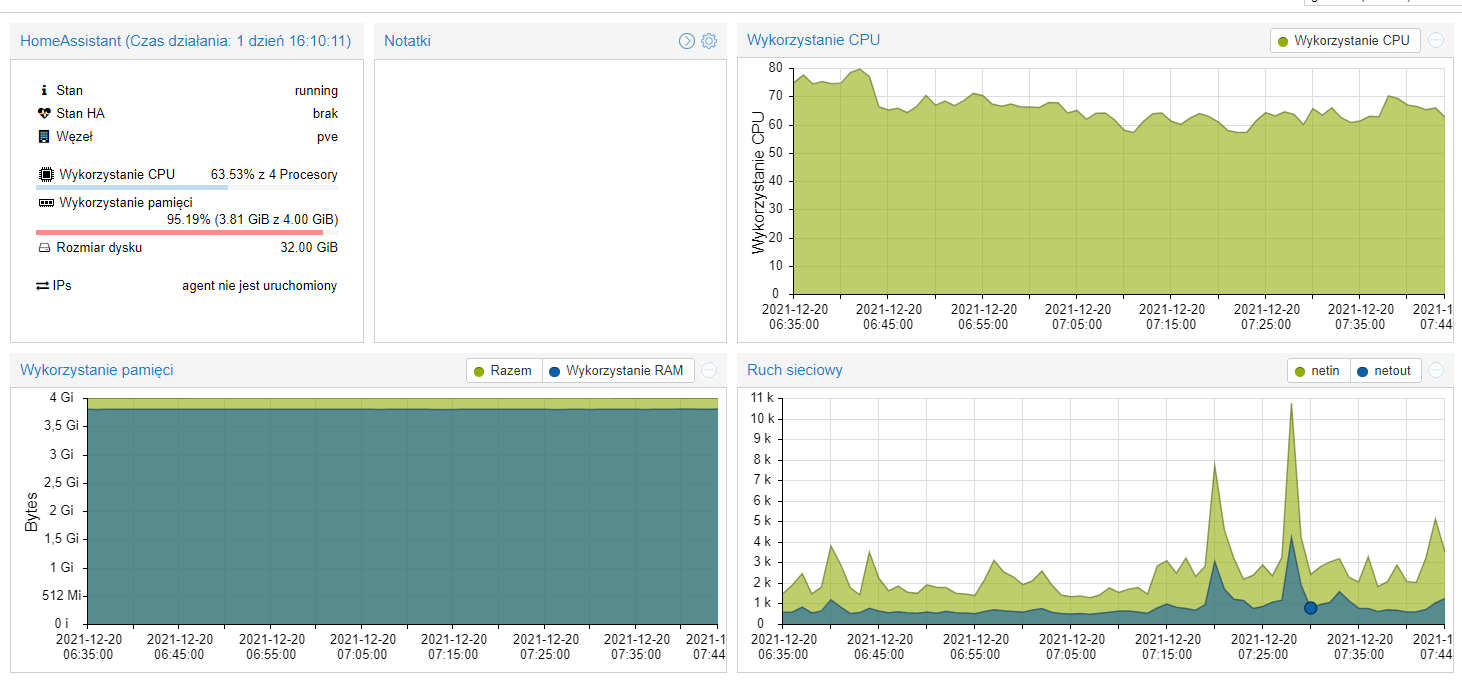
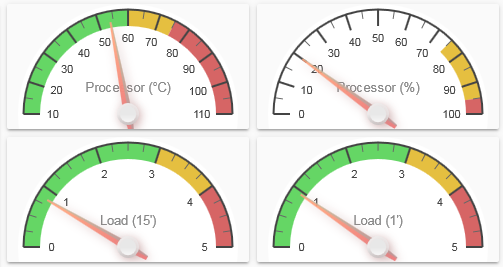
Takich testów nie da się zrobić w minutę - na 1 obrazku masz 15-minutowy Load 3,96 na 4 rdzenie, czyli praktycznie granica pracy realtime.
Jednominutowy to wciąż aż 3,22 (można to przeliczyć, że przekłada się to na ~ zajęte ponad 3
rdzenie, więc wcale nie jest wesoło - gdybyś odczekał z 5 minut byłoby lepiej widać czy rezultaty są pozytywne).
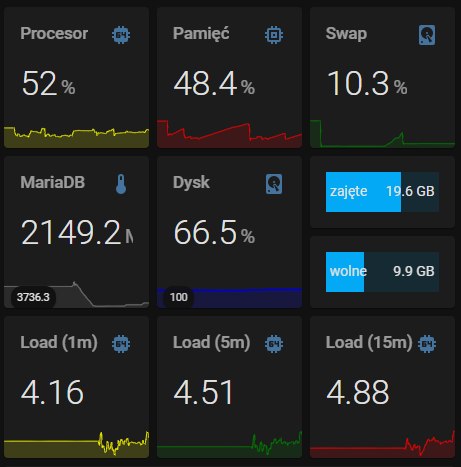
Swap jest zajęty w ~10%, czyli wydaje się, że sytuacja nie jest krytyczna, jakkolwiek na systemie z wystarczającymi zasobami przy standardowych ustawieniach swapiness jaki mamy w HAOS jego wykorzystanie powinno wynosić 0%.
Tak naprawdę nie widzę innej możliwości niż wykorzystanie sensorów Glances do monitorowania ogólnego stanu maszyny oraz sensorów Supervisora (które są defaultowo wyłączone, ale można je włączyć choćby tylko dla podejrzanych kontenerów) i późniejsza ich analiza.
Wykresik pamięci nieco przypomina sytuację z wyciekiem pamięci - jej wykorzystanie rośnie praktycznie liniowo, więc długookresowo może się skończyć wywrotką systemu - musisz po prostu monitorować sytuację, obejściem (ale nie rozwiązaniem!) problemu jest systematyczne restartowanie maszyny co jakiś czas - wydaje mi się, że @artpc gdzieś to opisywał - poszukaj, jeśli nie znajdziesz przyczyny (moim zdaniem trzeba szukać błędów w samych realnie użytych przepływach w NR, a nie NR jako takim).
zastanawiam się coraz bardziej żeby przejść na debiana… aktualnie mając samego proxmoxa i na nim HA działało fajnie ale ponoć sam proxmox trochę potrzebuję i lepiej będzie działać na samym debianie…
Moim zdaniem tak (gdy Load przekracza ilość dostępnych rdzeni), bo wtedy system przestaje działać realtime, tylko systematycznie łapie opóźnienie w przetwarzaniu danych - po krótszej lub dłuższej pracy w ten sposób opóźnienia zaczną być wyraźnie odczuwalne, a po jeszcze dłuższej przestaniesz je akceptować, ale inna kwestia jest taka, że nic się nie dzieje bez przyczyny.
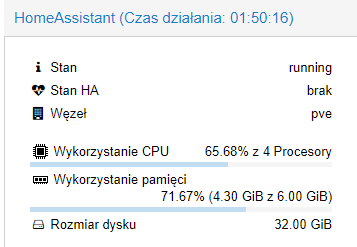
Natomiast jest jeszcze druga sprawa - na tym screenshocie coś mi mocno nie pasuje - ogólne obciążenie procesora masz zaledwie na poziomie nieco ponad 50%, a Load równocześnie sporo przekracza 4, niestety nie mam żadnej praktyki jeśli chodzi o wirtualizację w proxmoxie (nie jestem też ekspertem IT, więc nie traktuj mnie jako wyroczni!), więc mogę nie wiedzieć czegoś istotnego, co dotyczy twojej specyficznej konfiguracji - być może powinieneś przydzielić więcej procesora tej VM?
Jak dla mnie sam proces homeassistant zajmuje podejrzanie wielką ilość fizycznego RAMu (w tej chwili ~30% z 6GB).
Tak swoją drogą 6GB RAMu to niezbyt wiele jak na piętrową wirtualizację (zauważ, że same uruchomione kontenery używają sporo ponad 30GB wirtualnego RAMu, więc gdyby realne wykorzystanie przekraczało w nich 20% przydziału, to będą problemy, a sam proxmox też “powietrzem nie żyje”)…



 pożyjemy zobaczymy.
pożyjemy zobaczymy.