Chciałem wykorzystać noda counter
do “zabicia” nitki procesu (zatrzymania dalszego jej przebiegu) tak aby co 5, 7 czy 10 wiadomość (określona w liczniku) przechodziła dalej proces, po czym licznik się resetował i liczył od nowa.
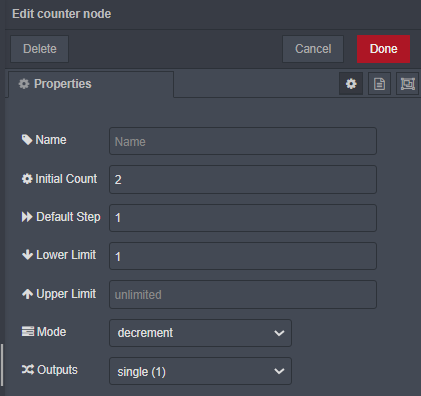
msg. do nodu COUNTER dociera co 15 sekund. (wyzwalając w nim akcje) każda akcja to COUNTER-1 (odejmuje zawartą w nim wartość o 1 - czyli liczy 6;5;4;3;2;1 i kiedy jest 0 daje msg. na wyjście i resetuje licznik. Kiedy jest wartość licznika większą niż 0 zabija proces - na wyjściu NULL.
Co chce osiągnąć?
Co 15 s. sprawdzana jest temperatura, jeśli przekroczy ona wartość krytyczną, msg. jest kierowane na ścieżkę - która wysyła powiadomienie z alarmem. Nie chcę dostawać tej wiadomości co 15 sekund tylko nie częściej niż co 1,5minuty (6 cyklu wywołania procesu)
Może licznik nie jest dobrym rozwiązaniem… Może lepiej ten licznik zastąpić nodem który uruchamia stoper na np. 90sekund i przez ten czas działania stopera zamienia wszystkie kolejne msg. inicjujące ten stoper na NULL na wyjściu (do póki działa kolejne msg. inicjujące go nie uruchamiają od nowa), a ten inicjujący (pierwszy) puszcza na wyjście. Po zakończeniu odliczania, stoper resetuje się i czeka na kolejny msg. inicjujący.
Według mnie o wiele lepiej do tego sprawdzi się nod delay.
Pierwsza wiadomości o krytyczniej temp ustawia nie na 1,5 minuty. Jeżeli spadnie poniżej w tym czasie to zatrzymuje delay jeżeli jest dalej to działa co 1,5 minuty
Próbowałem, ale okazało się że on opóźnił tylko wysyłkę. Na zasadzie odczekał i puścił serie.
każdy msg. inicjujący poszedł dalej, tylko że z opóźnieniem
To chyba można ogarnąć względnie prosto. Nie mam jak teraz tego sprawdzić. Możesz sprawdzać czy poprzedni stan był powyżej czy poniżej krytycznej wartości i ignorował te które i tak nic nie zmieniają.
I tu tkwi diabeł, bo wartości z czujnika mają bardzo dynamiczny przebieg. W ciągu 15sec może być różnica 1,5st C Funkcja po stwierdzeniu że jest temperatura krytyczna lub powyżej kieruje msg. na tą nitkę msg. prowadzącą do wysłania powiadomienia i drugą obsługującą automatyzację przeciw działaniu kryzysowi.
I ten nod miał być filtrem ograniczającym ilość wysyłki, żebym po nocy nie musiał kasować 300 maili. na każde 5 min akcji.
Jeżeli wartość jest poniżej krytycznej (załóżmy 30C) to nic się nie dzieje.
Jeżeli wartość jest krytyczna (np powyżej 30C) to idzie komunikat do Ciebie.
I teraz problem
Chcesz dostać tylko jeden komunikat na zmianę z temperatury dobrej na złą? Chcesz ignorować gdy jest ze złej na złą.
Czy chcesz dostawać co 1,5 minuty gdy ze złej na złą?
Pomysł na rozwiązanie:
porównanie old_state czy jest < krytycznej wartości - tak oddzielisz pierwszą wiadomość od reszty i te kolejne możesz ignorować
Zdefiniuj zmienną kontekstową typu flow i inkrementuj ją przed wysłaniem wiadomości jeżeli jest poniżej 6 czy tam ile chcesz to nie wysyłasz jeżeli powyżej to wysyłasz i ustawiasz ją na 1 czy tam 0
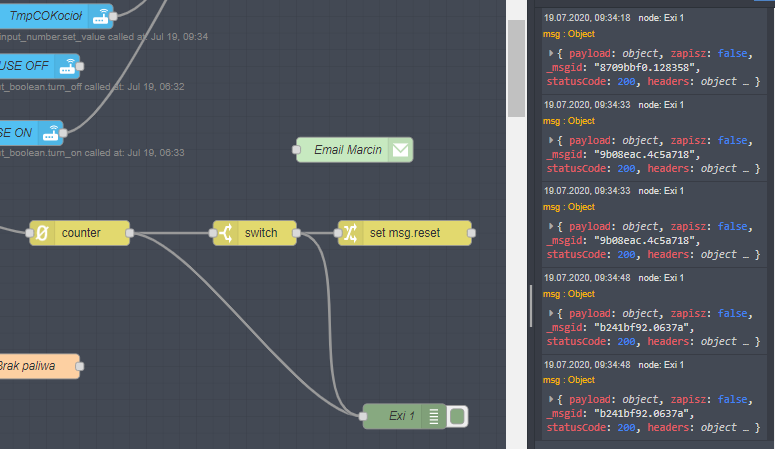
OK. ZADANIE WYKONANE
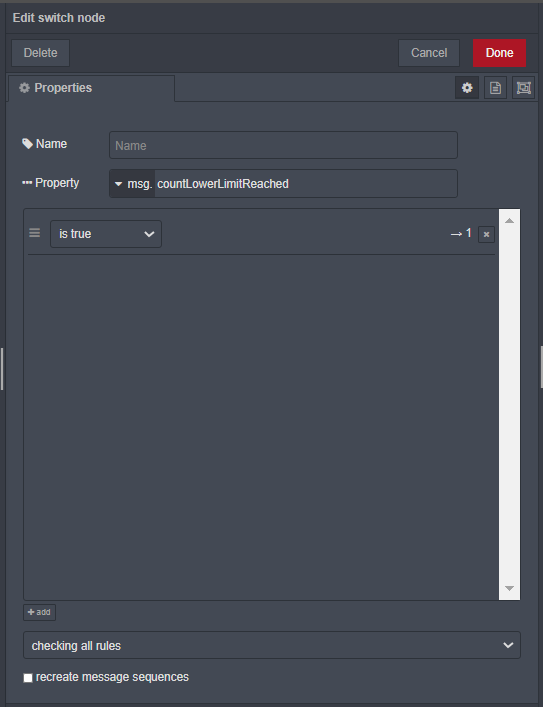
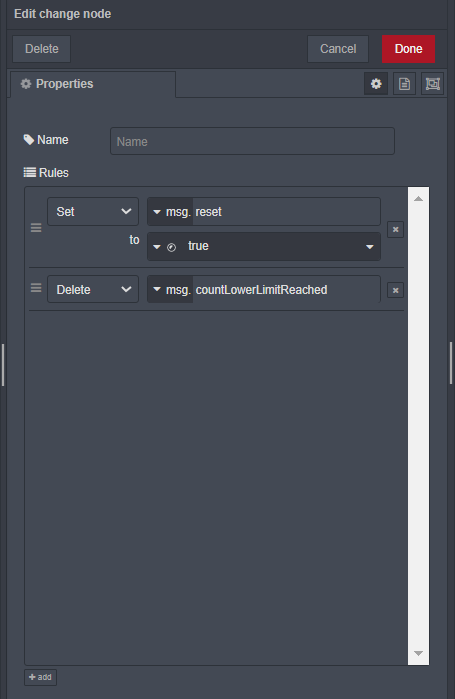
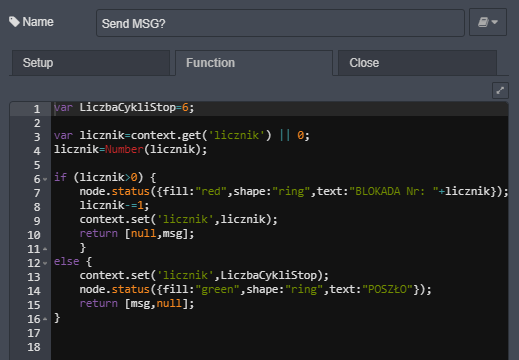
Pozostałem przy liczniku. Rozwiązałem problem za pomocą funkcji która w nitce procesu stanowi bramkę pozwalającą na przejście co siódmej wiadomości msg.
Poniżej msg. był generowany ręcznie do celów testowych działania bramki