Namówiony przez @szopen do popełnienia tego postu chciałem się z Wami podzielić “przygodą”, jak przytrafiła mi się ostatnio z moją instancją HA, w której zaczęło padać wszystko po kolei…
Ale od początku.
Zaczęło się od nieprawdopodobnych lagów w sieci zigbee, sięgających …kilkunastu minut.
Np. wchodzę do domu i zamykam drzwi uzbrojone w czujnik. Mimo, że zamknąłem za sobą drzwi i czujnik jest zwarty, to i tak przez co najmniej 20 minut leci z głośników komunikat “Otwarte drzwi, pacanie!”… Można było oszaleć… Tym bardziej, że sygnalizacja otwartych drzwi uniemożliwiała wykonanie innych automatyzacji, np. uzbrojenie alarmu, który uznał, ze dom nie jest zabezpieczony na tyle aby się uzbroić. Podobne lagi zaczęły pojawiać się także na innych urządzeniach. Irytacji nie było końca…
Doszedłem do wniosku, że rozsypała się sieć zigbee. Serwer raz po raz zaliczał śmierć kliniczną, która objawiała się zżeraniem RAM’u do 100%, wykorzystaniem SWAP’a do 100% i zajętością procka do 97%. Wszystko się gotowało… Jedyne, co mi pozostawało to twardy reset serwera… aż do kolejnej jego śmierci…
Na porcie 4357 zaczęły się też pojawiać jakieś dziwne komunikaty w stylu Observer NOT HEALTHY lub Observer NOT SUPPORTED. Byłem załamany, bo zacząłem zdawać sobie sprawę, że powoli tracę prawie rok swojej pracy nad deploymentem HA. Wszystko jak krew w piach!
W prawdzie kopie zapasowe robiły się regularnie do chmury Google, ale nie wiedziałem, czy są one na tyle zdrowe, by było z czego odtworzyć tę pracę, gdy zawiodą już wszystkie procedury naprawcze przewidziane dla HA.
Wykonałem wszelkie dostępne kroki ratunkowe z poziomu terminala typu su repair, nawet odważyłem się cofnąć wersję HAOS o dwa oczka, ale na nic się to nie zdało. Degradacja postępowała w tempie geometrycznym… i wkrótce pacjent umarł. Twardy reset bowiem także nie przywracał mu życia. Nie było z nim żadnego kontaktu poza wciąż poprawnymi odpowiedziami na zaczepki typu ping <adres_IP> -t, co świadczyło jedynie o tym, że host HA jest poprawnie wpięty do sieci LAN.
Złożyłem pacjenta “do grobu” i …przeprowadziłem jego reinkarnację zasiewając na jego dysku nowy HAOS wg tej instrukcji. Do portu USB wpiąłem świeżo dostarczony SkyConnect zamiast Conbee II. Zainstalowałem na powrót wszyskie dodatki (bez uruchomienia).
Na sczęście udało mi się wczytać mój backup, ściągnięty wcześniej z chmury na lokalny komputer ale jednocześnie powyłączałem wszystkie dodatki i integracje.
Sieć zigbee oparłem tym razem na integracji ZHA, pozostawiając świeżą instalację Z2M tylko jako opcję zapasową do przyszłej obsługi bardziej opornych urządzeń. Wiązało się z potrzebą ponownego sparowania wszystkich urządzeń z donglem SkyConnect (niestety migracja z Z2M nie powiodła się pomimo kilku prób, co ostatecznie przekonało mnie o możliwych przyczynach dramatycznych opóźnień w sieci zigbee, o kórych pisałem tutaj.
Zrobiłem research NR, którego @szopen słusznie podejrzewał o leaking pamięci i zacząłem metodycznie analizować przepływ za przepływem. Plan pracy był taki:
- Wyłączyłem wszystkie aktywne zakładki na dashboardzie NR
- Zacząłem deployować każdą z nich osobno zaczynając od najprostszych, sprawdzając przy tym pilnie jak jej uruchomienie wpływa na zasoby serwera
- Po każdym udanym uruchomieniu danej zakładki (założyłem, że uruchomienie będzie udane wtedy, gdy zasoby sprzętowe nie zostaną pożarte przez uruchomione przepływy) robiłem kolejną kopię zapasową.
- Kroki powtarzałem dla każdej zakładki osobno, aż wreszcie jedna z nich faktycznie ujawniła swoje niszczycielskie oblicze niczym pirania, zżerając RAM do zera, co po kilku minutach spowodowało także, że SWAP wyniósł 100%, po czym serwer kolejny raz całkowicie odmówił współpracy.
- Po zidentyfikowaniu trefnej zakładki (i wykonaniu
restorez najświeższej kopii sprzed chwili) wyłączyłem ją i zacząłem przenosić poszczególne logiczne jej składniki na zakładkę roboczą. Każdy taki ruch kończył się deploymentem tylko zakładki roboczej i natychmiastową analizą dostępności zasobów. Wciąż nie zapominałem o robieniu kopii zapasowych…
W ten sposób ujawniłem cztery nody, których deployment czynił niezdatnym do dalszej pracy całe środowisko HA (zżarty RAM = 100%, SWAP` = 100%, zajętość CPU = 97% i w efekcie końcowym “śmierć kliniczna” serwera).
Te 4 nody wyglądają niewinnie:
[{"id":"1287ec357b2fad2c","type":"poll-state","z":"b1a59f7a37c16498","name":"Temp. pieca","server":"869cd94c.d8cc48","version":2,"exposeToHomeAssistant":false,"haConfig":[{"property":"name","value":""},{"property":"icon","value":""}],"updateinterval":"","updateIntervalType":"num","updateIntervalUnits":"minutes","outputinitially":false,"outputonchanged":true,"entity_id":"sensor.control_cc1_flowtemperaturesensor_21222100209650938031177n9","state_type":"str","halt_if":"","halt_if_type":"str","halt_if_compare":"is","outputs":1,"x":775.7142944335938,"y":150,"wires":[[]]},{"id":"d89841c5f1efa4bc","type":"poll-state","z":"b1a59f7a37c16498","name":"Bojler tryb","server":"869cd94c.d8cc48","version":2,"exposeToHomeAssistant":false,"haConfig":[{"property":"name","value":""},{"property":"icon","value":""}],"updateinterval":"","updateIntervalType":"num","updateIntervalUnits":"minutes","outputinitially":false,"outputonchanged":true,"entity_id":"sensor.tryb_pracy_bojlera","state_type":"str","halt_if":"","halt_if_type":"str","halt_if_compare":"is","outputs":1,"x":445.71429443359375,"y":150,"wires":[[]]},{"id":"15741b4a2808e8f5","type":"poll-state","z":"b1a59f7a37c16498","name":"Piec tryb","server":"869cd94c.d8cc48","version":2,"exposeToHomeAssistant":false,"haConfig":[{"property":"name","value":""},{"property":"icon","value":""}],"updateinterval":"0","updateIntervalType":"num","updateIntervalUnits":"minutes","outputinitially":false,"outputonchanged":true,"entity_id":"sensor.tryb_pieca","state_type":"str","halt_if":"","halt_if_type":"str","halt_if_compare":"is","outputs":1,"x":445.71429443359375,"y":200,"wires":[[]]},{"id":"7c1333baab7f663d","type":"poll-state","z":"b1a59f7a37c16498","name":"Temp. bojlera","server":"869cd94c.d8cc48","version":2,"exposeToHomeAssistant":false,"haConfig":[{"property":"name","value":""},{"property":"icon","value":""}],"updateinterval":"0","updateIntervalType":"num","updateIntervalUnits":"minutes","outputinitially":false,"outputonchanged":true,"entity_id":"sensor.control_dhw_domestichotwatertanktemperature_212221002026096538031177n9","state_type":"str","halt_if":"","halt_if_type":"str","halt_if_compare":"is","outputs":1,"x":775.7142944335938,"y":200,"wires":[[]]},{"id":"869cd94c.d8cc48","type":"server","name":"Home Assistant","version":5,"addon":true,"rejectUnauthorizedCerts":true,"ha_boolean":"y|yes|true|on|home|open","connectionDelay":true,"cacheJson":true,"heartbeat":false,"heartbeatInterval":"30","areaSelector":"friendlyName","deviceSelector":"friendlyName","entitySelector":"friendlyName","statusSeparator":"at: ","statusYear":"hidden","statusMonth":"short","statusDay":"numeric","statusHourCycle":"h23","statusTimeFormat":"h:m","enableGlobalContextStore":true}]
Cały problem wziął się stąd, że nie określiłem zawczasu częstotliwości odczytu 4 sensorów w nodach pool state błędnie zdefiniowanych w pliku sensors.yaml, przez co encje te w ogóle nie istniały. NR przyjął więc najmniejszą jednostkę domyślną ich odczytu: 1ms. Efekt był oczywisty: każdy z tych nodów odpytywał o nieistniejącą wartość swojego sensora aż 1000 razy na sekundę. Może komputer kwantowy dałby sobie z tym radę, ale zwykły NUC po prostu wymiękł… I wcale mu się nie dziwię, też bym wymiękł ![]()
Nawiasem mówiąc szkoda, że nie ma w NR jakiegoś bardziej zaawansowanego mechanizmu walidacji danych już na etapie ich wprowadzania, pewnie szybko wyłapałbym swój błąd i zaoszczędziłbym sporo czasu, stresu i roboty.
Te ‘trefne’ sensory to tak na prawdę atrybuty encji climate.piec_vaillant, które zamieniłem na odrębne encje (sensory), a które miały mi w prosty sposób pokazywać czy bojler/piec:
- są załączone
- czy obieg jest podgrzewany
- czy pompa pracuje
- jaka jest temperatura pieca a jaka bojlera
- w jakim programie (predefiniowanym przez producenta:
home,away,day,night,party,auto,off) urządzenia pracują w danej chwli - u mnie piec i bojler mogą pracować w róznych programach jednocześnie, niezależnie od siebie…
Nie jestem jeszcze zbyt biegły w płynnym korzystaniu ze składni językowej JSON czy Javascript, dlatego łatwiej mi było operować wartościami encji (po to je stworzyłem, niestety z błędami), niż ich atrybutami…
A na dodatek integracja Vaillant (Multimatic) jest wyjątkowo trudna do opanowania i konfiguracji, nie wpomnę o kiepskiej i nieintuicyjnej dokumentacji…
Po całej akcji naprawczej teraz mam tak:
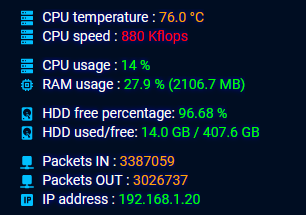
![]()
Więc chyba mogę odtrąbić sukces, czego i Wam życzę w podobnych sytuacjach ![]()
{kind=link}