Moi Drodzy,
Od dłuższego czasu używam czterech identycznych czujników otwarcia drzwi/okien Develco WISZB-120. W funkcji sygnalizacji otwarcia wszystkie pracują bez zarzutu. Ale od ponad 3-ech miesięcy dwa z nich wysyłają potwierdzenie zamknięcia z gigantycznym opóźnieniem, sięgającym nawet kilkunastu minut! Pozostałe dwa nie mają takiego problemu i sygnał zamknięcia wysyłany jest natychmiast.
Nigdy nie zmieniałem lokalizacji tych sensorów, ten problem pojawił się dość nagle. Zasilanie bez zarzutu, baterie wymieniane regularnie. Mam po domu rozsiane różne inne urządzenia zigbee (zasilane z sieci 230V), które pełnią rolę wzmacniaczy sygnału, więc trudno podejrzewać, że jest za mały zasięg (tym bardziej, że przy otwieraniu sensory te wykazują bezbłędną orientację - problem dotyczy tylko zamykania).
Próbowałem chyba wszystkiego, łącznie z ‘twardym’ usunięciem obu feralnych sensorów z HA i powtórnym ich sparowaniem (zawsze udanym). Wygląda na to, że eletronika jest OK, źródło błędu leży chyba gdzie indziej… Ale gdzie?
A może jest tak, że błędne czujniki wysyłają komunikat o zamknięciu całkiem poprawnie, ale sam komunikat zostaje gdzieś zbuforowany i czeka na coś? (np. na powtórne potwierdzenie zamknięcia?) Byłoby to jednak niezgodne z zasadą działania sensora binarnego, który wysyła przecież swój stan z chwilą jego zmiany a nie w momencie, który sobie ‘upodoba’.
Jedyna widoczna różnica w ustawieniach urządzeń jest następująca:
-
Poprawnie dziające czujniki mają tak:
-
Natomiast te dziające błędnie mają tak:
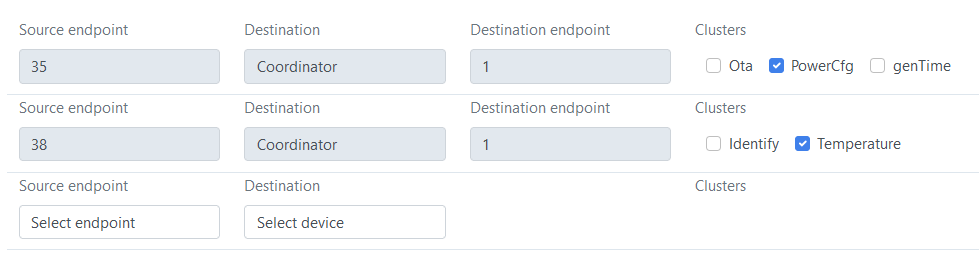
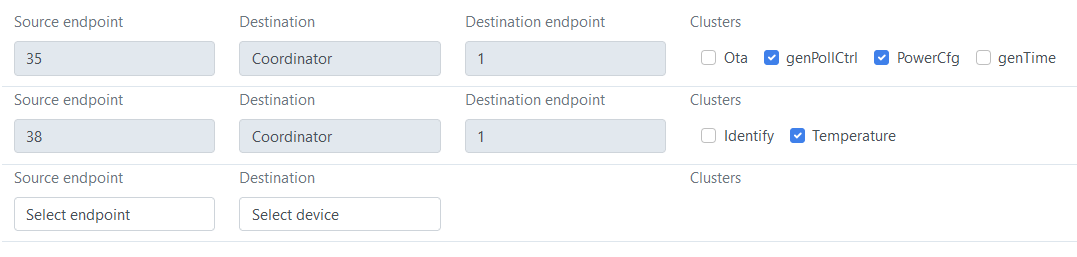
Oczywiście widać różnicę w polu genPollCtrl, problem jest jednak taki, że w błędnych czujnikach nie da się tego odznaczyć (chwilę po odznaczeniu pole to samoczynnie zaznacza się z powrotem).
Proszę Was o pomoc, gdyż dziwne zachowania obu czujników uniemożliwiają poprawną pracę m.in. system alarmowego, generuje też szereg innych niepożądanych implikacji…