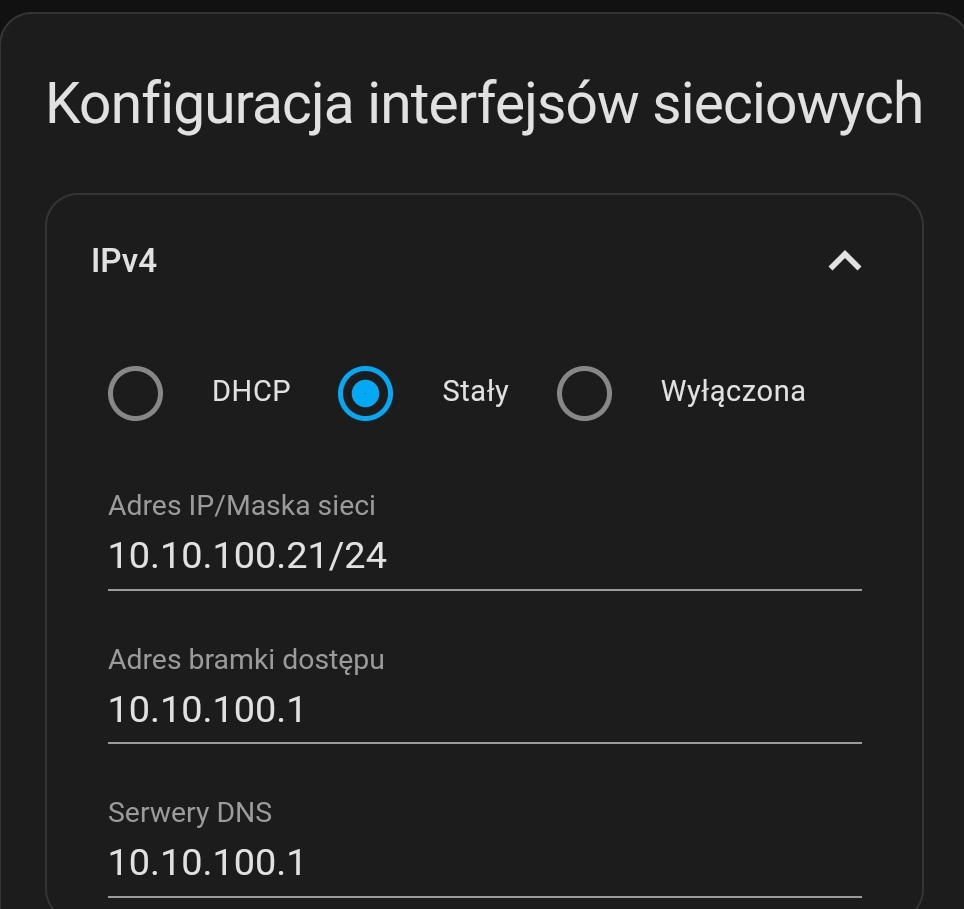
Tylko tak sobie myślę, czy jeśli wcześniej adres 10.10.100.21 byl przydzielony do HA, które było uruchomione jako VM w Proxmox, a sam Proxmox miał 10.10.100.20, to czy rzeczywiście przydzielając teraz adres 10.10.100.21 bezpośrednio do HA nie ma jakiegoś konfliktu? Muszę sprawdzić na routerze, bo rzeczywiście tam może być jakiś konflikt.
Edit:
Rzeczywiście problem powodował konflikt adresów. W tablicy ARP do adresu 10.10.100.21 był przypisany inny MAC niż powinien być. Po wyczyszczeniu śmieci w ARP połączenie wstało. Na próbę pobrałem dodatki i działa.
Dziękuję @szopen za podpowiedź, dobrze naprowadziłeś.
No wlasnie rozważałem instalację HAOS bo dla mnie najważniejsza jest automatyka HA i moze spróbuje z tej strony. A przy okazji pytanie czy po wyjeciu dysku m2 i włożeniu do adaptera usb mogę zrobić mu format a pozniej dopiero obraz przez balene ?
Jeśli Balena Ether sobie poradzi, to nie musisz nic formatować wcześniej (teoretycznie powinna widzieć ten dysk jako dysk fizyczny), jeśli sobie nie poradzi, to musisz popracować nad partycjonowaniem (a właściwie “zdepartycjonowaniem”), moim zdaniem najłatwiej zrobić to w linuksowym gparted, ale dróg jest wiele (tyle że Windows w przypadkach gdy Balena sobie nie radzi raczej wymaga narzędzi partycjonowania dostępnych tylko w linii poleceń, bo z trudnymi przypadkami okienkowy diskmgmt.msc sobie nie poradzi, chociaż próbować oczywiście można; a formatowanie tak naprawdę nie jest niezbędne, bo i tak obraz jest przepisywany 1:1 na dysk fizyczny i powstanie tam 1 partycja EFI + 7 partycji typowo linuxowych).
Właściwie to myślę, że jakieś 99% możliwych sytuacji jest już opisanych w tym wątku powyżej, więc w razie problemów sugeruję go poczytać w całości (dawno nie aktualizowałem tutorialka, ale nie instaluję HAOS-generic co chwilę).
PS Standardowa instalacja w proxmoxie polega na instalacji HAOS-ova (więc to też HAOS tylko instalowany na wirtualnym sprzęcie), natomiast HAOS dostosowany do pracy na sprzęcie fizycznym to HAOS-generic.
Hej! Jestem jeszcze trochę zielony, kupiłem Dell WYSE i zainstalowałem HA właśnie jako bare metal dzieki tutorialowi na yt. Z tego co widzę niemal dokładnie ten sam sposób co w tym wątku.
Mam na dellu wbudowane 16gb + 128gb nvme. Założyłem, że zainstaluje system na tych 16gb a później dla konkretnych dodatków będę mógł wskazać jako storage ten dodatkowy dysk? Czy lepiej było zainstalować os od razu na tych 128gb?
Mnie się wydaje że spokojnie można tak zrobić, system zainstalować na maluchu na większy dysk migrować bazą danych. Może @szopen wypowie się w tym temacie i podpowie co jego zdaniem będzie dla Ciebie i systemu korzystniejsze.
@mintpanda nie wskazujesz miejsca dla Dodatków, migracja dotyczy całej partycji danych (więc przeniesie się cała jej zawartość) @MariuszAK
To nie jest wyłącznie kwestia samej bazy danych - przenosimy w jednym ruchu całą partycję roboczą.
Oczywiście, że można tak zrobić, i powiem więcej - tak bym zrobił mając dysk roboczy w tak małym rozmiarze (128GB to wcale nie jest dużo) i równocześnie do wykorzystania malucha 16GB zdatnego na system (na podstawie dostarczonych informacji nie wiem czy to ssd czy eMMC, ale nie robiłbym z tego zagadnienia). U siebie obecnie mam HAOS na “maluchu” (tam gdzie mam taką możliwość) mimo dysku na partycję roboczą w rozmiarze 240GB. Ten wybór jest związany tylko z jedną kwestią - trwałości dysku roboczego (nawet te kilka GB zaoszczędzone na statycznych danych - partycjach systemowych przedłuży o kilka % trwałość dysku z kopią partycji hassos-data a właściwie jej “pomigracyjnym” odpowiednikiem hassos-data-external, ten % jest tym większy im mniejszy jest dysk roboczy).
@Krzyszof_K
Natomiast generalnie to jest taka sytuacja “na dwoje babka wróżyła”/“jeden rabin powie: tak, drugi rabin powie: nie”.
Do rozważenia jest kilka zmiennych i każdy musi sobie sam na to dać odpowiedź - gdzieś o tym pisałem właśnie na tym forum w jakimś pokrewnym temacie (jeśli nawet nie tu gdzieś wyżej) pewnie do znalezienia, więc nie będę ponownie męczył tematu.
Edit: Chciałem podlinkować, ale nie mogę znaleźć tego co wspomniałem tutaj (możliwe, że ten temat był drążony bardziej na PW niż na forum i przez to niewiele po nim zostało…).
W każdym razie oprócz ewidentnego plusa w postaci wydłużenia trwałości ssd o kilka % (co przy planowaniu trwałości rozwiązania rzędu 10 lat może mieć znaczenie) wykorzystanie eMMC ma też delikatne minusy, a rozpatrywałem takie kwestie:
zwykle sporo mniejsza wydajność eMMC w porównaniu do ssd (sata, czy szczególnie nvme), znaczenie tej kwestii jest w sumie pomijalne - przeciętna eMMC ma prędkości zapisu zwykle sporo mniejsze od nawet budżetowych ssd, ale zapisy tam robimy w zasadzie tylko przy aktualizacjach systemu (więc ta kwestia nie jest istotna), niestety prędkości odczytu są też zwykle mniejsze niż ssd (tu przepaść nie jest zwykle aż tak wielka jak przy zapisie, oczywiście w konkretnym wypadku należałoby porównywać konkretne dane), prędkość odczytu ma wpływ na czas startu systemu - w pierwszej chwili po migracji systemu z ssd na eMMC naprawdę się zastanawiałem czy to ma sens (start systemu jest zauważalnie dłuższy), ale biorąc pod uwagę, że system właściwie uruchamiamy “raz na ruski rok” a przez resztę czasu pracuje, uważam, że ten minus jest w zupełności "do przełknięcia"
wbrew powszechnym mitom, że pamięci flash nie zużywają się w trakcie odczytu, to nie jest prawda (te informacje pochodzą bezpośrednio od ich producentów), jakkolwiek wpływ odczytów jest od tysięcy do milionów razy mniejszy od wpływu zapisów na zużycie nośnika (dlatego zwykle jest on po prostu pomijany w typowych zastosowaniach), jednak biorąc pod uwagę swoje długotrwałe eksperymenty uznałem ten fakt jako coś o pomijalnym wpływie.
Mimo to zakładam, że nie należy wykorzystywać na system nośnika o stopniu zużycia powyżej 90% (czyli z raportowanym pozostałym czasem życia 10% lub niższym), jest to o tyle istotne, że w ramach ekologicznej mody często decydujemy się na sprzęt używany/poleasingowy/zezłomowany, gdzie stopień zużycia może być wysoki (HAOS jak na razie jest w stanie pokazać stan niektórych nośników eMMC jeśli mamy na nich instalację w całości, reszta powszechnie dostępnych narzędzi niestety nie pokazuje stanu).
łatwość migracji partycji danych w przyszłych wersjach HAOS (uzupełniony zestaw skryptów będących bazą dla funkcji w GUI ma pojawić się w HAOS 10.0 i kolejnych, ale w HAOS 9.x część z nich jest już dostepna), no to akurat plusik jakkolwiek malutki.
@mintpanda
Ponieważ jesteś dopiero na starcie, to nie masz nic do stracenia by spróbować instalacji na “maluchu” i w zasadzie natychmiastowej migracji partycji danych na ten większy dysk (przy okazji przetestujesz, czy wbudowane skrypty w HAOS 9.5 już dobrze działają dla nvme, bo jeśli się nie mylę znaczące poprawki migracji są dopiero w jeszcze nie opublikowanym HAOS 10.0, ale wersja rc3 wciąż nie nadaje się do normalnej pracy (jeszcze nie usunięte niekompatybilności systemu i niektórych Dodatków) - można tymczasowo przejść na kanał beta i zaktualizować do 10.0.rcX, gdyby w 9.5 jeszcze nie było dobrze działającej migracji, a po migracji zrobić downgrade systemu do 9.5 (to nie są żadne cuda na kiju - do cofania wersji jest potrzebny Dodatek terminala lub lokalna konsola).
PS
@mintpanda Pochwal się co to KONKRETNIE za sprzęt i czy były jakieś niespodzianki (tj. jakiekolwiek odstępstwa od najprostszej drogi instalacji, czy w BIOSie są dostępne bezpośrednio wszystkie potrzebne opcje itd.)
Wszystko co tu napisałem odnosi się do instalacji HAOS-generic (oraz HAOS dedykowany dla SBC, bo tam jest identyczne rozwiązanie, choć nie o tym tu mowa), nie ma zastosowania dla żadnych innych metod instalacji (“debianowa”, supervised, core, czy chyba najmodniejsza dzięki całej masie tutoriali wirtualizacja np. w proxmox)
Gdy pisałem ten minitutorial nie było jeszcze żadnych poradników wideo, ponieważ nie instaluję HAOS co chwila, więc potrzebuję feedbacku użytkowników by utrzymać go w stanie umiarkowanie aktualnym.
Ja niedawno właśnie na wyse 5070 pentium 8/128 instalowałem has generic
Jako ze nie obyty z linuxem trochę mi zajęło czasu (oglądanie filmików z instalacji)
1Odpaliłem z pendrive ubuntu
2 zamknąłem kreatora instalacji
3.zainstalowalem haos za pomocą [Balena Etcher
4 odpaliłem instalacje haos ale wybrałem od razu dysk 128
5 wszystko się bez problemu zainstalowało
Wskazówki/problemy
1trzeba było wybrac w biosie botowanie z usb jest troche dalej w menu(sa filmiki pokzujace bios dela)
2.podczas instalacji za pomocą Balena Etcher trzeba wklepac w terminal 3 linijki w/g instrukcji na stronie)
Źle zadałem pytanie - chodziło o różnice względem tych umieszczonych w powyższym tutorialku, te komendy
są konieczne w aktualnych wydaniach Ubuntu (bo Balena Ether jest oparta na przestarzałej technologii)
“pod HA” się nie da, ale mamy przecież Dodatki (tutaj tagiem jest smart od skrótu stosowanej technologii S.M.A.R.T.)
jeśli chodzi o platformę systemmonitor, to jest świetna, bo zasadniczo nie zużywa zasobów pobierając informacje i tak już dostępne w systemie (warto monitorować z jej poziomu w szczególności użycie procesora, RAMu i swapa, ale parę innych parametrów tez można).
Jeśli chcesz na szybko podejrzeć pewne kluczowe parametry, to zawsze można to zrobić w terminalu - przykładowo free -h pokazuje “obłożenie pamięci”
sytuacja normalna, gdy masz np. Dodatki, które chwilowo zużywają ogromną ilość pamięci, ale ją prawidłowo zwalniają
~ $ free -h
total used free shared buff/cache available
Mem: 9.6G 2.0G 331.3M 5.1M 7.3G 7.5G
Swap: 2.4G 768.0K 2.4G
sytuacja w systemie, gdzie można wyjąć jeden z 2 DIMMów (jest 8GB = 2x 4GB) i nie wpłynie to ujemnie na wydajność
~ $ free -h
total used free shared buff/cache available
Mem: 7.7G 1.1G 4.2G 2.2M 2.3G 6.4G
Swap: 1.9G 0 1.9G
(jeśli zawsze widzisz dużo free, to znaczy, że masz zainstalowane za dużo RAMu w stosunku do realnych potrzeb, więc można wtedy zoptymalizować wykorzystanie wyjmując nadmiarowe moduły ), oprócz tego są np. interaktywne polecenia top czy htop (to ostatnie dostępne pod warunkiem zainstalowania alternatywnego dodatku terminala jeśli się nie mylę).
Również Dodatek Glances daje możliwość interaktywnego podejrzenia co się dzieje (jakkolwiek podczas korzystania z jego interfejsu sam zużywa spore zasoby), natomiast eksponuje całą furę sensorów w swojej Integracji
o dzięki ogarnęła mnie pomroczność ze nie wpadłem na smart:)
glanced czytałem ale to kobyła wiec na razie nie ma sensu
inne potestuje
A co proponujesz z pytaniem o bazę danych?
zastanawiam się nad baza danych (mariadb) czy warto zamieniać z tej domyślnej
teraz puki pustawaczy kiedys (juz na wiekszy dysk) zmigracją z sqlitle na mariadb
O bazie nic mądrego nie powiem - kiedyś motywacja do użycia innej bazy była większa, bo to co oferowała “fabryczna” sqlite2 było naprawdę biedne, ale od czasu wprowadzenia długoterminowych statystyk motywacja spadła mi niemal do zera (a jeśli mam ręcznie grzebać w bazie, to już na wstępie mi się nie chce z tego “doktoryzować”, bo aby używać niestandardowej bazy, to najpierw trzeba mieć niezerowe pojęcie o bazach danych, a ja bym swoje określił jak bliskie zera :P) i nadal motywacja maleje - po tym co widzę jakie kłody pod nogi mają rzucane użytkownicy innych baz danych (no generalnie każde niestandardowe rozwiązanie wymaga od jego użytkownika więcej uwagi i roboty od “gotowców”).
Witam , jakiś czas temu zainstalowałem ha os , wszystko ładnie ale kopie które zrobię przywracają się kilkanaście godzin. Czy to możliwe że przez to że wcześniejsza kopia była z instalacji HA na Debianie. Proszę o pomoc . Kopie nie ważą dużo maks 700mb.
Nie mam pojęcia, za mało danych.
Nie bardzo rozumiem czemu przywracasz co chwilę kopie zapasowe.
Ale możliwe, że musisz znaleźć jakieś składniki, które wywołują konflikty.
Jeżeli kopie na Debianie były robione wcześniej, np. Przed dużą aktualizacją Bazy Danych, gdzie była wielka zmiana w konstrukcji Bazy Danych HA to przywracanie takiej kopii wiąże się z kilku godzinną aktualizacją.