Poczytaj tutaj, może znajdziesz rozwiązanie
Frigate dynamicznie się rozwija, w opracowywanej dokumentacji do wersji 0.14.0 (na razie Beta) widzimy już jak wiele nowych rzeczy będzie dostępnych. Projekt mocno zmierza w rozwijaniu funkcjonalności rejestratora i łatwiejszej obsługi z GUI.

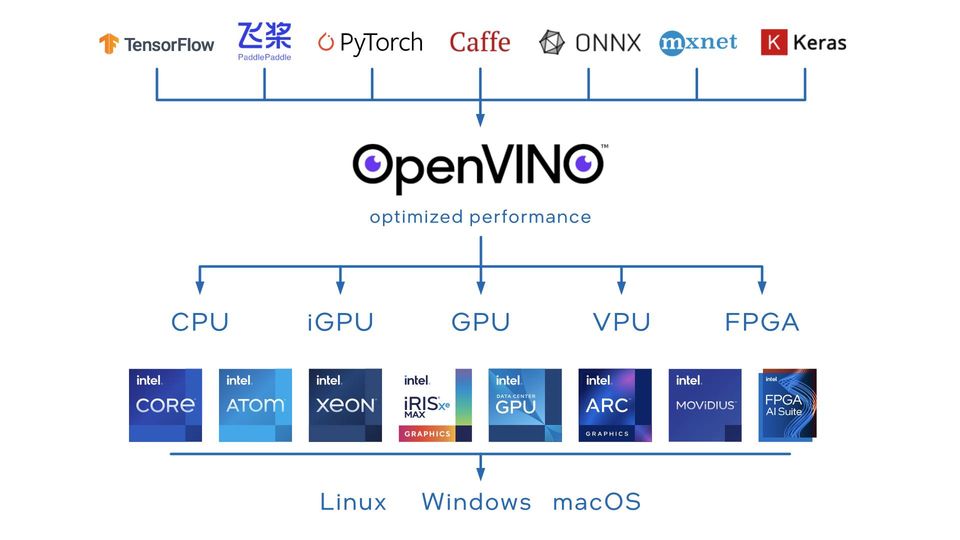
Mam pytanie do użytkowników Frigate, którzy korzystają z detektora i modeli opartych na oprogramowaniu Openvino. Chodzi o wykorzystanie układów graficznych Intela zintegrowanych z procesorami.
Czy rzeczywiście nowy procesor N100 uzyskuje przy Openvino lepszą wydajność we Frigate niż Google Coral TPU?
Czy ktoś wykorzystuje inne modele i konwertuje je do OpenVINO IR?
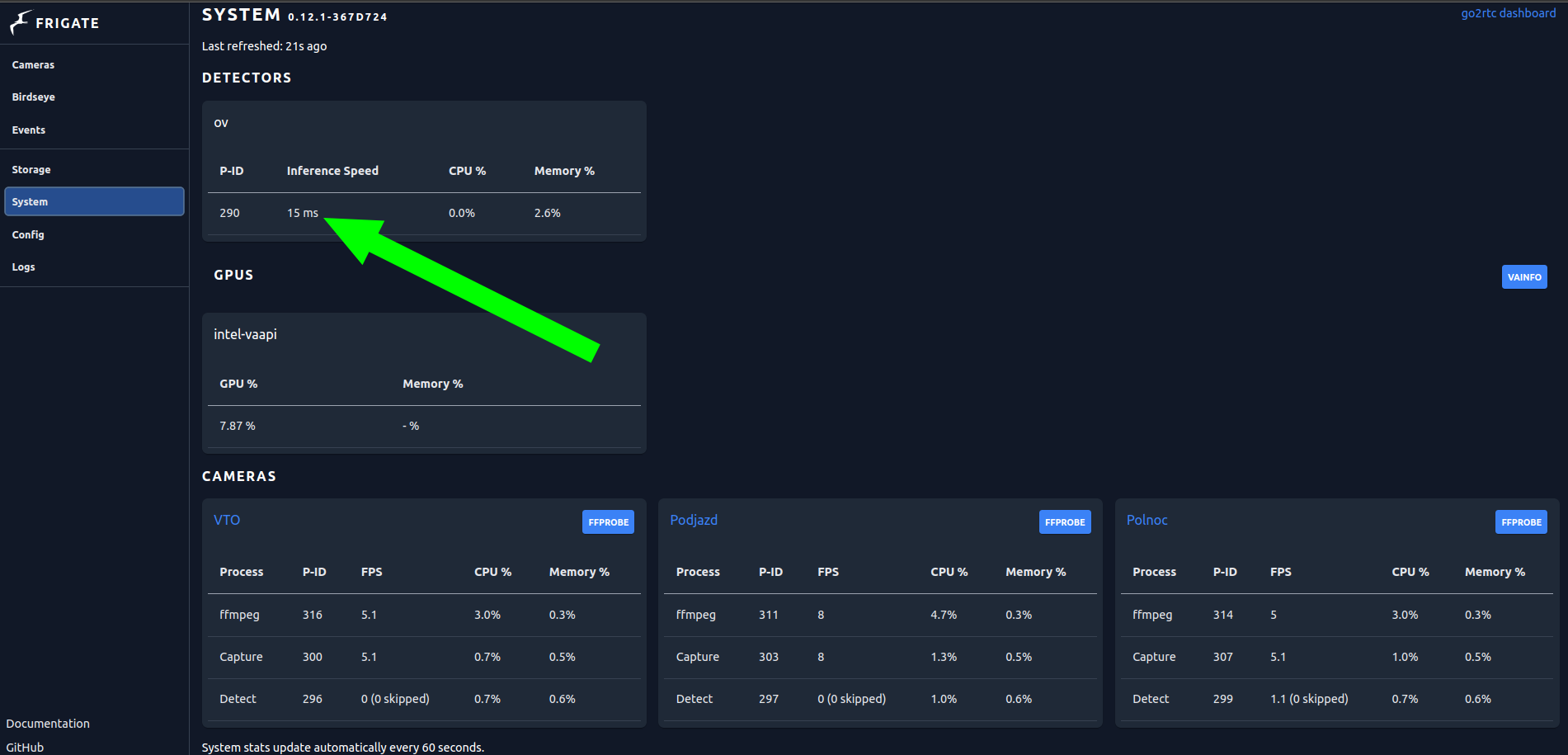
Nie otrzymałem żadnych odpowiedzi, więc postanowiłem sam sprawdzić na swoim nowym, warsztatowym mini PC Firebat AM02 z Intel N100 i jestem pod dużym wrażeniem ile za tak niewielkie pieniądze osiąga ten sprzęt. Frigate odpalone dla moich trzech kamer bez Coral TPU za to z wykorzystaniem OpenVINO Detector. Całość pracuje testowo w kontenerze Docker na Linux Mint 21.3 z Kernel 6.5.0-41-generic.
Zrzut z Frigate w wersji 0.12.1
oraz dla wersji 0.13.2, która teoretycznie bardziej obciąża sprzętowe zasoby hosta
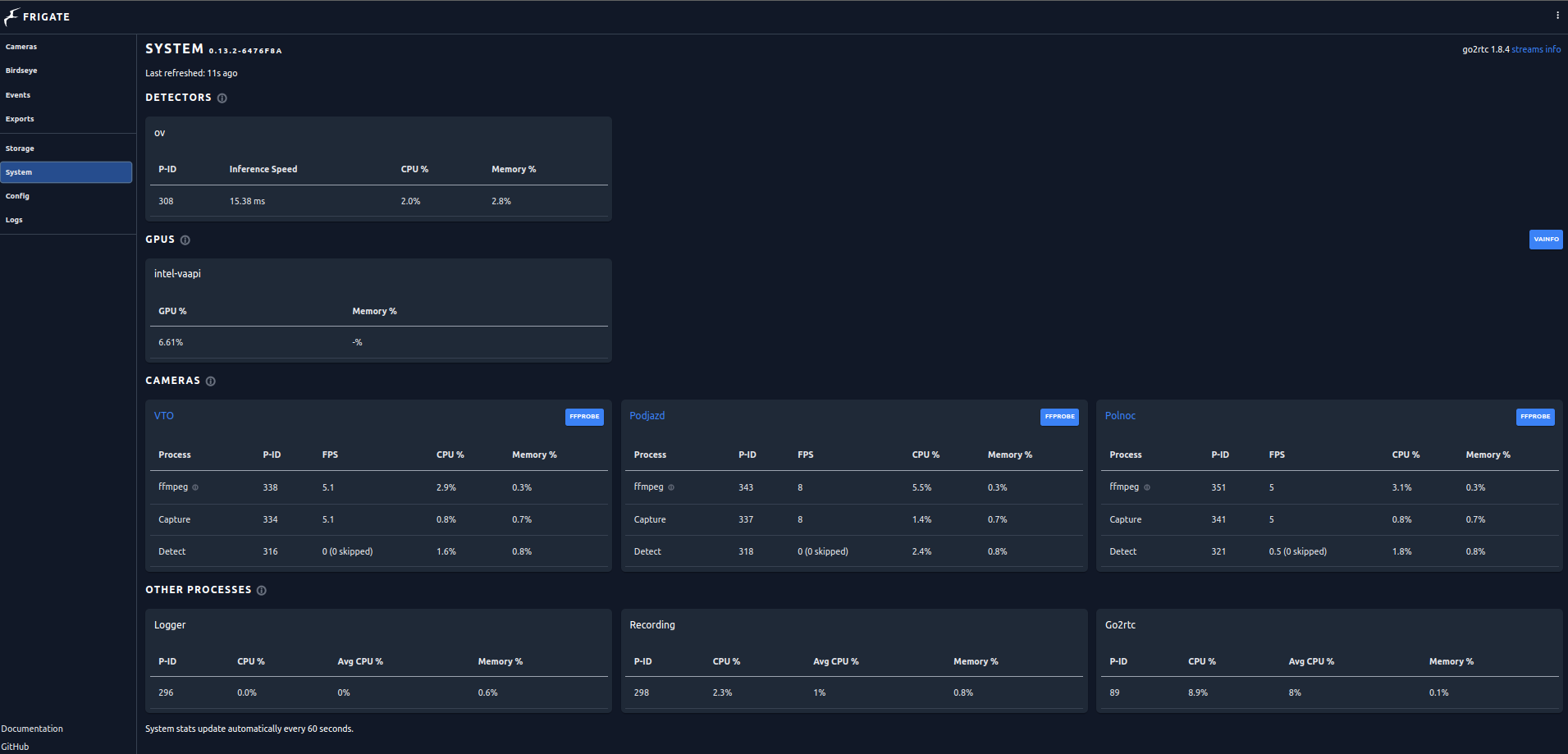
Mogę stwierdzić z przekonaniem, że nie ma potrzeby używania Coral TPU dla nowszych generacji iGPU Intela. Pozostanie przetestowanie w praktyce modeli OpenVINO, podobno tu też jest lepiej niż w standardzie z TensorFlow Lite.
EDIT:
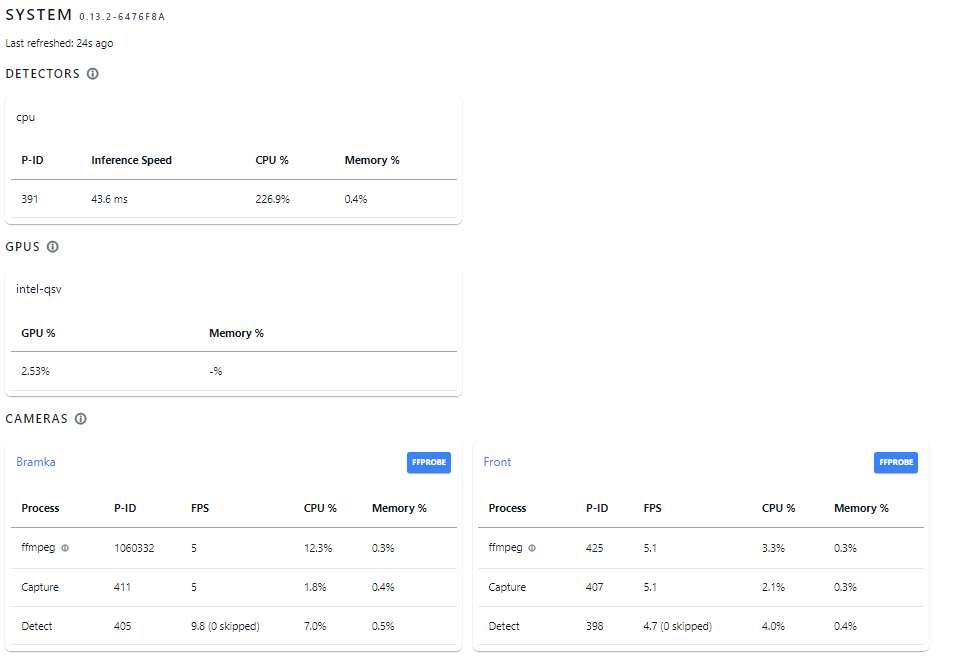
Kolejny test, tym razem Frigate jako AddOn HA na maszynie z Intel J5005 i detektorem OpenVino oraz akceleracją sprzętową
ffmpeg:
hwaccel_args: preset-vaapi
Wyniki całkiem znośne.
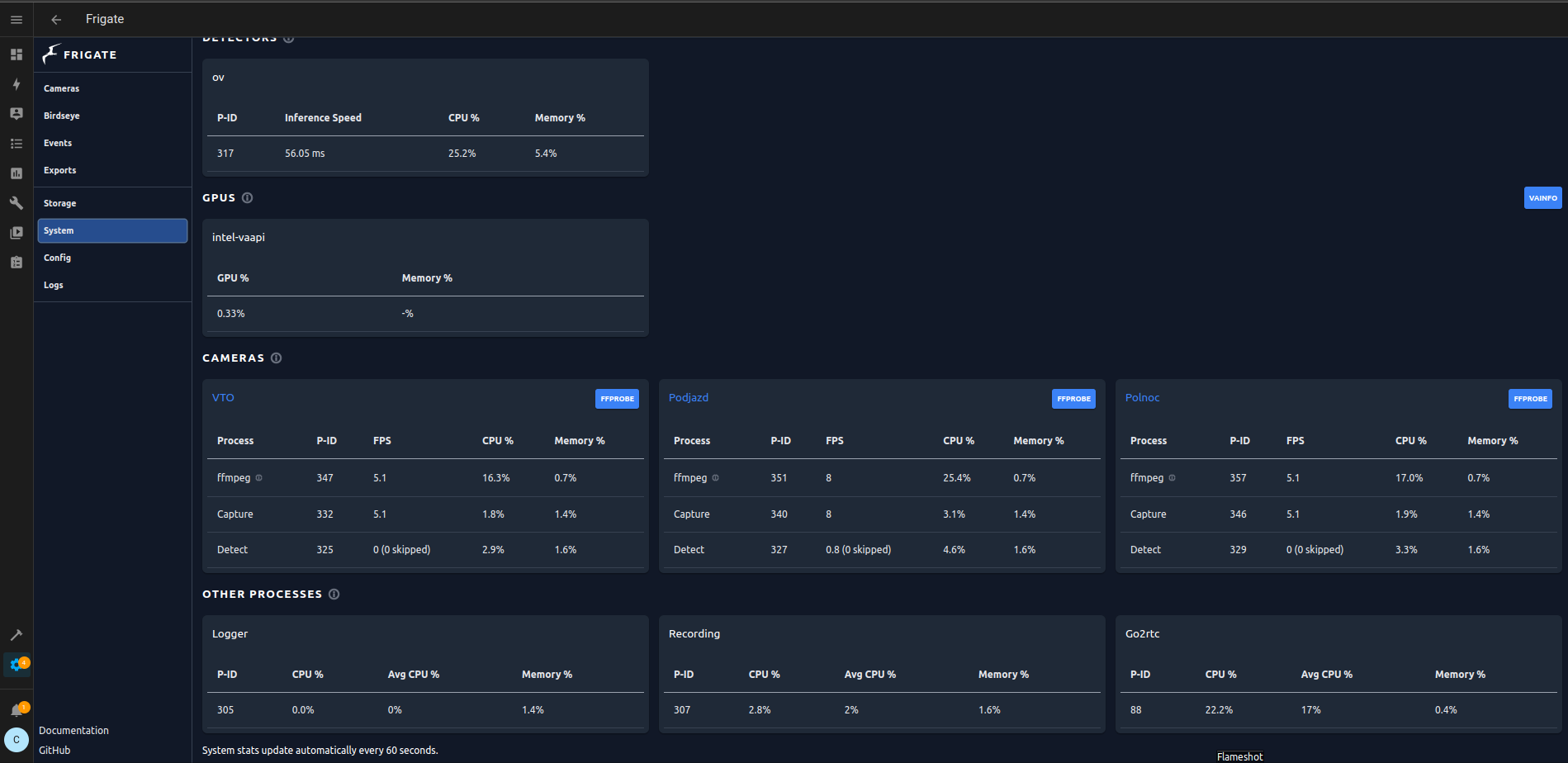
3 polubienia
2,26 rdzenia jest zajęte w 100% (inaczej mówiąc - jeśli to się dzieje na jednym rdzeniu to jest to jakieś 0.44x wolniej niż realtime)
tzn. jeśli to jest w linuxowej mierze obciążenia procka - to wtedy każdy rdzeń jest traktowany jako 100%
więc 4-rdzeniowy CPU daje się obciążyć w 400% i procesy dzieją się nadal w realtime (o ile są to procesy wielowątkowe, że mogą pracować na różnych rdzeniach)
w dzisiejszych czasach sprawy się skomplikowały, bo kiedyś w SMP wszystkie procki (czyli dzisiaj rdzenie) były identyczne, nie wiem jak jest to obecnie liczone dla CPU zbudowanego z niesymetrycznych rdzeni (jak choćby N100 o którym tu mowa była)
inference to jest czas potrzebny na analizę zdjęcia/klatki
haha nawet nie wiedziałem, że jest jakieś FAQ
1 polubienie
Detekcję normalnie mam wyłączoną ( włączyłem tylko dla próby i porównania), wtedy CPU=0%.
Wykorzystuje analitykę wbudowaną w kamerę, która na potrzeby automatyzacji generuje zdarzenia.
Ja mam Frigate uruchomione na różnych platformach. Produkcyjnie działa z Coral TPU i tu detektor osiąga ok 6-7ms prędkości wnioskowania. To jest w sumie główny parametr jaki oceniam. Drugim jest zajętość CPU, bo bardzo przekłada się na energochłonność całego procesu w starszych sprzętach, nawet przy optymalizacji parametrów strumieni. Tu ponownie przy OpenVino miło zaskakuje mnie J5005, który pomimo obciążenia w granicach 25-30% wszystkich 4 rdzeni przy przetwarzaniu ruchomego obrazu konsumuje ok 7-10W prądu (HAOS, prawie surowy). Ale całe te eksperymenty mają na celu potwierdzenie, że nie potrzebuję koniczynie Coral przy N100 oraz sprawdzenie czy modele AI OpenVino będą pozbawione fałszywych detekcji. Zwłaszcza w porównaniu do standardowych i przy tym samym ustawieniu parametrów kamer.
Dokumentacja Frigate jest dobra ale wymaga poszerzenia wiedzy z całego tematu aby była zrozumiała, bo wszystko rozbija się o szczegółową konfigurację w pliku config.yalm, a niuansów dla każdego przypadku jest wiele.
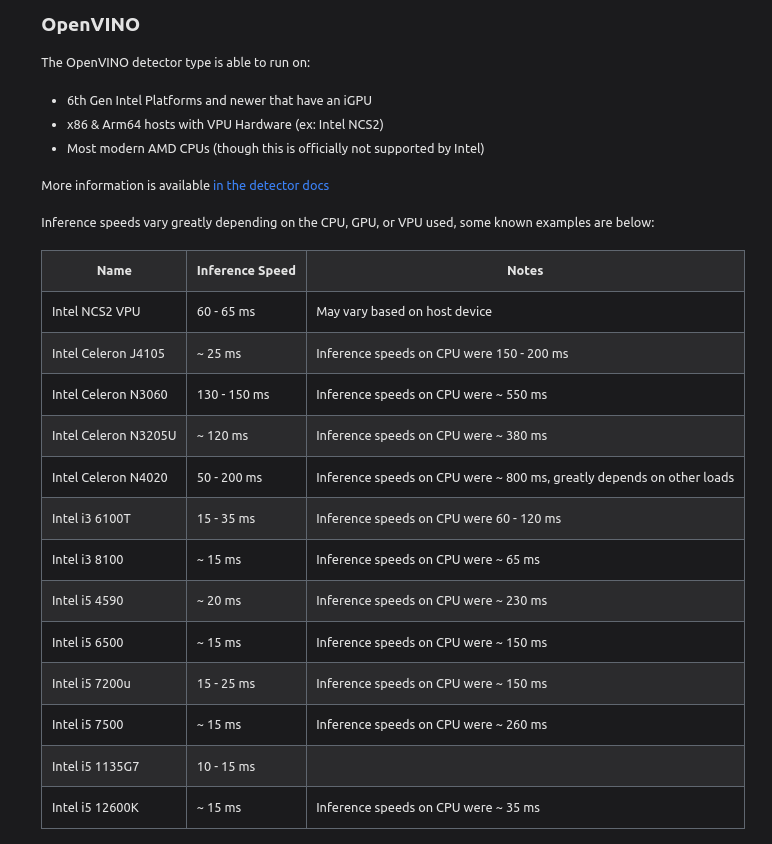
Taka ciekawa, poglądowa tabela na koniec:
tak z ciekawosci jaki masz sprzet pod frigate? Chodzi mi o serwer i dyski. Bo zakladam ze te wszelkie minipc nie maja slotow na hdd 3.5 a nikt nie przeplaca za te 4tb+ dyski ssd ani tez nie dodaje osobnej obudowy i zasilania pod 3.5?
Czy wszyscy leca na NASach?
Ja mam blaszaka z Intel i5 4gen jako domowy NAS ale to nie ma zbyt większego znaczenia, bo ja jestem zbieraczem i lubię eksperymentować, dłubać. Jest na rynku ciekawa konstrukcja, która ma sporo klonów i pozwala na umieszczanie dwóch dysków 3,5" a dodatkowo ma złącze M2 NVME/SATA.
Tu czyjaś prezentacja, specyfikacje są różne ale obudowa i płyta bardzo podobna dla każdej z dostępnych kombinacji. W tym Intel N100…
Gdybym miał doradzać, to jeśli ktoś ma rejestrator w takiej czy innej formie, to lepiej go wykorzystać dla tego konkretnego zastosowania i Frigate mieć jako dodatek równolegle. Jeśli się nie ma dedykowanego sprzętu pod kamery, to wystarczy jeden większy dysk dla Frigate lub zapis do NAS po sieci lokalnej, to jest kwestia mapowania. Frigate mocno rozwija interfejs w kierunku funkcjonalności typowego przeglądu nagrań.
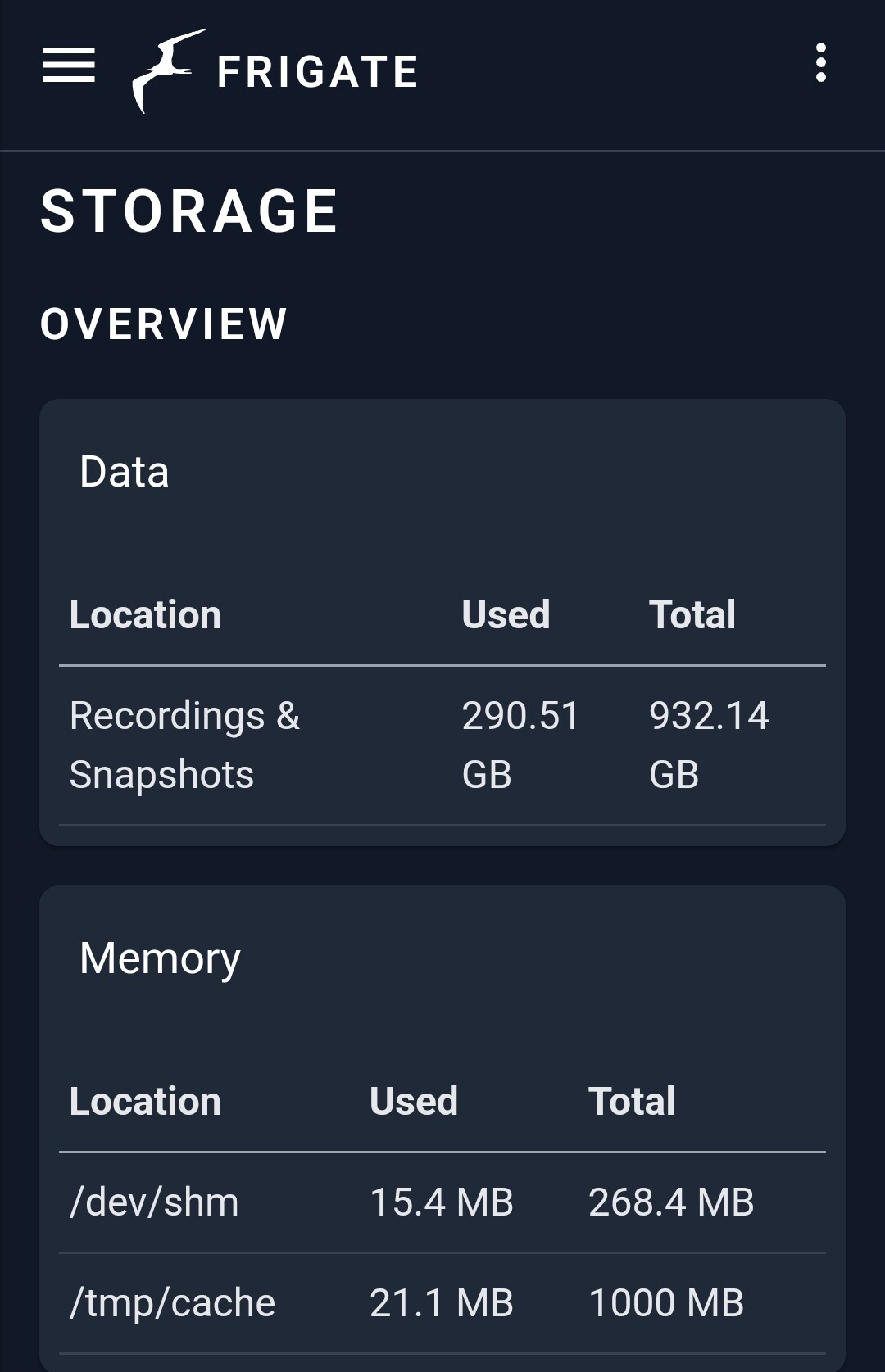
Ja osobiście nie nagrywam we Frigate ciągłego obrazu z kamer. Wystarczają mi klipy z detekcji obiektów. Ustawiłem na okres przechowywania dwa tygodnie i zajmuje to stosunkowo niewiele przestrzeni dyskowej.
2 polubienia
Hej! Zostałem poproszony na facebooku na grupie Home Assistant o przeklejenie mojego posta z doświadczeniami z Frigate’m i detekcją twarzy jak i tablic rejestracyjnych. Wklejam i tu, dla potomnych ![]()
Link do tego posta:
#detekcja_twarzy #tablice_rejestracyjne frigate #doubletake #compreface #aiserver
Detekcja Twarzy, Tablic Rejestracyjnych, Frigate - garść porad.
Hej!
Na grupie jestem krótko, ale zdążyłem zauważyć powtarzające się pytania o detekcję twarzy (i pytania o detekcję tablic rejestracyjnych).
Jako, że od ponad pół roku prawie codziennie dłubię w tych tematach, testuję różne technologie, tweakuje parametry - mam już nieco “wyczucia” co działa (u mnie), a co nie.
Ponadto stanowczo sprzeciwiam się stwierdzeniom “że jak AI to tylko GPU a Coral to zabawka”.
Mam CPU i Corala, moje AI działają wyśmienicie dlatego chętnie podzielę się tipami i odpowiem na pytania zagubionych entuzjastów ![]()
![]() A) Sprzęt:
A) Sprzęt: ![]()
![]() 1) NUC
1) NUC
- Intel NUC NUC13ANKi7 13th Gen Core I7-1360P
- RAM: 64G
- Coral Edge TPU - wersja USB-C, nie-rozwojowa
- HDD: SSD, 2TB, podzielone na system i Proxmox VMki + kontenery
![]() 2) Kamery + ustawienia strumienia na którym realizuję detekcję
2) Kamery + ustawienia strumienia na którym realizuję detekcję
= W sumie 5 kamer, 7 strumieni + detekcja audio
-
Reolink Doorbell PoE (5MP)
– 2560 x 1920
– FPS 15
– Bitrate: 4096
– I-frame Interval: 1x -
Reolink RLC-823A 16x (8MP)
– 3840 x 2160
– FPS 15
– Bitrate: 8192
– I-frame Interval: 1x -
2x Reolink TrackMix PoE
– 3840 x 2160
– FPS 15
– Bitrate: 8192
– I-frame Interval: 1x -
Reolink RLC-520
– 2560 x 1920
– FPS 15
– Bitrate: 7168
![]() B) Technologia
B) Technologia ![]()
![]() Frigate jako NVR, uruchomiony wprost na host’cie NUC
Frigate jako NVR, uruchomiony wprost na host’cie NUC
– wyłącznie korzysta z Corala TPU
– mam włączoną również detekcję dźwięku (rozmowa, szczekanie, krzyk)
![]() Double-Take
Double-Take
– (frontend) interfejs graficzny do detekcji twarzy i treningu sieci
– Korzystam z bardziej aktualnego forku oryginalnego repozytorium
– GitHub - skrashevich/double-take: Unified UI and API for processing and training images for facial recognition.
![]() CodeProject.AI
CodeProject.AI
– (backend) model wykrywający twarz
– Moduły:
— License Plate Reader
— Face Processing
– CodeProject.AI Server: AI the easy way. - CodeProject
![]() Frigate ALPR
Frigate ALPR
– (frontend) detekcja tablic rejestracyjnych
– GitHub - kyle4269/frigate_alpr
![]() Frigate ALPR Web
Frigate ALPR Web
– (frontend) Webowy interfejs do powyższego, umożliwia podgląd zdjęć aut, logi
– GitHub - kyle4269/frigate_alpr_web
![]() C) Konfiguracja
C) Konfiguracja ![]()
![]() 1. Setup serwera
1. Setup serwera
- Intel NUC to Ubuntu + Proxmox
- Proxmox uruchamia m.in. VMkę Ubuntu oraz kontener (CT) “frigate-container”
- na NUCu mam Frigate docker
- na Frigate-container (CT) mam Double-Take, CompreFace, CodeProject.AI server, Frigate-ALPR + Web
- w sumie na NUCu mam uruchomionych jakieś 40 dockerów do różnych celów
- Wszystkim zarządza Portainer.
![]() 2. YAMLe
2. YAMLe
Poniżej link do zanonimizowanych config’ów ww. technologii:
![]() D) FAQ
D) FAQ ![]()
![]() 1. Ile trwa detekcja twarzy?
1. Ile trwa detekcja twarzy?
- CodeProject.AI Server: 2-17 sekund.
– 2 sekundy jeśli pojawia się kilka klatek z twarzą.
– 17 sekund jeśli łażę wokół domu i Frigate mieli obraz ze wszystkich kamer, a twarz wykrywana jest dziesiątki razy.
– Najczęściej jednak twarz łapie do kilku sekund.
![]() 2. Czemu nie GPU?
2. Czemu nie GPU?
-
bo GPU żre prąd, a moja serwerownia (Synology NAS + Reolink NVR + NUC + kilka urządzeń) żre już 3.5kWh dziennie.
-
bo GPU to armata do muchy. Nie potrzebuję detekcji twarzy czy obiektu w milisekundy, zadowala mnie kilka sekund

-
bo NUC i Coral TPU wymiatają i nie potrzebuję GPU - wszystko sprowadza się do dobrej konfiguracji
-
W rozważaniu CPU vs GPU warto wziąć pod uwagę następującą obserwację:
– Modele detekcji twarzy głównie konsumują pamięć RAM, na potrzeby przechowywania w pamięci ciężkiego modelu (nawet kilka GB!)
– Kiedy detektory nie pracują, ich konsumpcja CPU jest bliska zeru.
– Zanim klatka z kamery pójdzie do detekcji, analizowana jest pod kątem czy w ogóle twarz na niej występuje (filtr OpenCV), czy spełnia kryterium obiektu (czy to w ogóle sylwetka osoby?), czy spełnia inne kryteria (min_area)
– To oznacza, że w praktyce nieliczne klatki są poddawana detekcji.
– To oznacza, że wysoka konsumpcja CPU ma charakter chwilowy, nieliniowy. -
Na załączonych obrazkach wydruk z “s-tui” oraz “ctop”, utylizacja CPU i RAMu przez kontenery oraz całościowo z serwera.
-
Widać, że CPU nie przekracza 33-40%.
-
RAMu całość (przypominam - ponad 40 dockerów, większość lab + praca) ok. 30GB
![]() 3. Czemu nie CompreFace?
3. Czemu nie CompreFace?
- bo CompreFace jest ciężkie jak cholera, żre dużo pamięci, nie nadąża z inferencją przy kaskadzie zdjęć na wejściu.
- To be fair, AI.Server także żre - ale w jednym pudełku mamy model Twarz + Tablice, a CompreFace daje tylko twarz.
- CodeProject.AI Server jako jedna aplikacja oferuje moduły różnych zastosowań - jeden system do tablic rejestracyjnych + twarzy
- bo z dyskusji na Double-Take sam autor forka twierdzi, że AI.Server lepiej sprawuje się na gołym CPU, CompreFace zaś na GPU:
CompreFace or CodeProject.AI Server? · skrashevich/double-take · Discussion #109 · GitHub
![]() 4. A tablice jak wykrywasz?
4. A tablice jak wykrywasz?
- domyślnie Frigate-ALPR zaleca korzystanie z online usługi “Plate Recognizer”
- darmowa subskrypcja w zupełności wystarcza, do 2500 requestów miesięcznie chyba.
- natomiast ja chciałem mieć model offline, u siebie w serwerowni. CodeProject.AI Server modułem “License Plate Recognizer” realizuje to.
- prywatność.
![]() 5. Jaki sprzęt muszę mieć by robić detekcję twarzy?
5. Jaki sprzęt muszę mieć by robić detekcję twarzy?
- ja jestem zwolennikiem rozwiązania Frigate + Coral na detekcję obiektów (osoba, auto) oraz CPU do twarzy.
- A zatem kup terminal z dobrym CPU - dużo rdzeni, dużo core’ów, daj mu dużo RAMu i kup Corala.
![]() 6. Coral jest za drogi. Jak żyć?
6. Coral jest za drogi. Jak żyć?
- detekcja obiektów na gołym CPU zarżnie Ci maszynę jak świnię. Nie polecam, testowałem.
- wtenczas inferencja rozciągnie się nawet do minut jeśli będziesz chciał jeszcze twarz i tablice.
- albo kupujesz Corala i używasz CPU albo GPU.
- GPU natomiast pożre Ci tyle prądu że nie wyjdziesz na tym ekonomicznie.
![]() 7. A testowałeś w ogóle GPU cwaniaku?
7. A testowałeś w ogóle GPU cwaniaku?
- Tak, dysponuję Intel NUC 11 Phantom Canyon wyposażonym w RTX 2060.
- Nie jest to bestia pośród GPU ale świetnie dźwigała Frigate’a, natomiast nie byłem zadowolony z konsumpcji prądu.
![]() 8. Po co Ci detekcja twarzy?
8. Po co Ci detekcja twarzy?
- otwieram furtkę gębą jak wracam z biegania, bez telefonu.
- jeśli kamera wykryje mnie wokół domu, automatyka wyłacza powiadomienia z kamer, wysyła powiadomienie “Mariusz kręci się przy szopie”, świecę podbitkę jeśli zgaszona, różne
![]() 9. Po co Ci detekcja tablic rejestracyjnych?
9. Po co Ci detekcja tablic rejestracyjnych?
- otwieram bramę gdy podjeżdża rodzina i znajomi, czy sam podjeżdżam.
- Istotnym jest, że tablice wykrywam tylko i wyłącznie kamerą z domofonu.
- Inne kamery powodowały false positive’y dla samochodów zaparkowanych na podjeździe.
![]() 10. Czy testowałeś inne backendy detekcji twarzy?
10. Czy testowałeś inne backendy detekcji twarzy?
- Tak, testowałem DeepStack (słaba detekcja), AWS Rekognition (duże koszta), CompreFace (duża konsumpcja zasobów - RAM + CPU, przeciętna jakość detekcji)
- Póki co najbardziej jestem zadowolony z CodeProject.AI Server
![]() 11. Jak NUC radzi sobie z tymi zadaniami?
11. Jak NUC radzi sobie z tymi zadaniami?
- Utylizacja CPU nie przekracza 40%.
- Frigate + Coral inferencja na poziomie 6-8ms
![]() 12. A Home Assistanta gdzie uruchamiasz?
12. A Home Assistanta gdzie uruchamiasz?
- Na osobnym terminalu, HP T630.
- Jeśli Cię to interesuje, na końcu tego posta znajdziesz nick do opisu mojego setupu HA
![]() 13. Przyszedłem się Ciebie czepiać - w innych komentarzach pisałeś że używasz CompreFace, aaa i co teraz kłamco?!!11
13. Przyszedłem się Ciebie czepiać - w innych komentarzach pisałeś że używasz CompreFace, aaa i co teraz kłamco?!!11
- Testuję od dłuższego czasu CodeProject.AI server i na etapie pisania tych komentarzy nie byłem pewien czy go polecam.
- Wtenczas polecałem CompreFace’a.
- Teraz polecam AI Server.
- Idź hejcić gdzieś indziej.

![]() 14. Jak Double-Take wykrywa twarze?
14. Jak Double-Take wykrywa twarze?
- Double-Take nie wykrywa twarzy, on jedynie łączy Frigate’a z magiczną skrzynką która robi detekcję.
- DT działa tak:
– 1. Nasłuchuje na MQTT zdarzeń frigate/events
– 2. Jeśli zdarzenie jest typu “person” oraz spełnia wymóg “min_area” oraz “camera” rozpoczyna pracę.
– 3. Odpytuje Frigate’a o dwa zdjęcia: “latest.jpg” oraz “snapshot.jpg” . Wykonuje to X razy, tyle ile skonfigurowaliśmy (u mnie 6 razy jedno i 6 razy drugie) co Y czasu (u mnie co 300ms).
– 4. Każde zdjęcie sprawdzane jest czy w ogóle jest tam twarz (filtr OpenCV)
– 5. Jeśli jest twarz, całe zdjęcie wysyłane jest do backendu detekcji (CompreFace, AI.Server).
– 6. DT odczekuje “timeout” na odpowiedź (np. 25 sek).
– 7. Jeśli odpowiedź przyjdzie, to analizuje czy wykryto znaną twarz. Twarz musi spełnić kryterium minimalnego rozmiaru oraz pewności (confidence) zanim zostanie “zaakceptowane”.
– 8. Jeśli odpowiedź nie przyjdzie w zadanym czasie, DT dalej nie czeka na model. Zamyka połączenie.
![]() 15. Czy Intel NUC to jedyne słuszne rozwiązanie? Drogo.
15. Czy Intel NUC to jedyne słuszne rozwiązanie? Drogo.
- Absolutnie nie! Kupiłem NUCa do potrzeb wielorakich (do pracy, do labu, do AI właśnie)
- Spokojnie możesz poczytać tutaj na grupie i poszukać alternatywnego terminala wyposażonego w rozsądne CPU, dorzucić mu pamięci - i powinien udźwignąć.
- Koledzy w komentarzach (i w innych postach) piszą o zaletach terminala opartego N100, poszukaj na grupie
![]() E) Hints, Tips & Tricks
E) Hints, Tips & Tricks ![]()
![]() 0. Instalację jakiegokolwiek oprogramowania gorąco polecam poprzez Portainer → Stacks . YAML zgodny ze specyfikacją “docker-compose” ułatwia zmiany ustawień, re-deployment. Nigdy nie wpisuję z palca “docker run --dupa”.
0. Instalację jakiegokolwiek oprogramowania gorąco polecam poprzez Portainer → Stacks . YAML zgodny ze specyfikacją “docker-compose” ułatwia zmiany ustawień, re-deployment. Nigdy nie wpisuję z palca “docker run --dupa”.
Portainer to oprogramowanie do zarządzania dockerami. Instalujemy ja na naszym host’cie, pozwoli nam ładnie startować, sprawdzać, zmieniać dockery.
![]() 1. Detekcję obiektów (Frigate) prowadze na strumieniu o najwyższej rozdzielczości. To istotne, bo nim więcej pikseli tym większa jakość detekcji, pewność.
1. Detekcję obiektów (Frigate) prowadze na strumieniu o najwyższej rozdzielczości. To istotne, bo nim więcej pikseli tym większa jakość detekcji, pewność.
![]() 2. Na kamerach ustawiam niższe FPS (np. 15 zamiast max 30), tak aby FFMPEG mógł nadążyć z obróbką strumienia, inaczej gubił klatki.
2. Na kamerach ustawiam niższe FPS (np. 15 zamiast max 30), tak aby FFMPEG mógł nadążyć z obróbką strumienia, inaczej gubił klatki.
![]() 3. Zanim Double-Take wyciągnie twarz do detekcji, najpierw nasłuchuje zdarzeń “person” z Frigate’a. Następnie wyciąga 6 zdjęć “latest.jpg” oraz 6 “snapshot.jpg” w odstępach 0.3sek (w sumie 1.8 sek). Ta konfiguracja jest efektem moich prób i błędów. Za dużo prób wyciągania wysyła za dużo klatek do detekcji i zamula CPU. Za duża zwłoka gubi szybko poruszające się osoby. Te parametry będę jeszcze optymalizował, nie są idealne
3. Zanim Double-Take wyciągnie twarz do detekcji, najpierw nasłuchuje zdarzeń “person” z Frigate’a. Następnie wyciąga 6 zdjęć “latest.jpg” oraz 6 “snapshot.jpg” w odstępach 0.3sek (w sumie 1.8 sek). Ta konfiguracja jest efektem moich prób i błędów. Za dużo prób wyciągania wysyła za dużo klatek do detekcji i zamula CPU. Za duża zwłoka gubi szybko poruszające się osoby. Te parametry będę jeszcze optymalizował, nie są idealne ![]()
Double-Take.yaml:
attempts:
# number of times double take will request a frigate latest.jpg for facial recognition
latest: 6
# number of times double take will request a frigate snapshot.jpg for facial recognition
snapshot: 6
# process frigate images from frigate/+/person/snapshot topics
mqtt: true
# add a delay expressed in seconds between each detection loop
delay: 0.3
![]() 4. Istotnym jest, że zanim Double-Take wyśle twarz do detekcji, wykrywa czy w ogóle twarz znajduje się w klatce wideo przy pomocy filtrów OpenCV. To bardzo oszczędza CPU/GPU i odrzuca wiele klatek.
4. Istotnym jest, że zanim Double-Take wyśle twarz do detekcji, wykrywa czy w ogóle twarz znajduje się w klatce wideo przy pomocy filtrów OpenCV. To bardzo oszczędza CPU/GPU i odrzuca wiele klatek.
![]() 5. We Frigate’cie bardzo istotnym jest optymalizacja parametrów stref, mask obiektów, min_area, max_area i innych które wykluczają fałszywe detekcje osób - np. mi wielokrotnie tuje wykrywa jako osobę. Niestety Frigate’a trzeba non stop konfigurować wykluczając strefy, modyfikując parametry. Naszym celem jest zmniejszenie ilości zdarzeń “osoba”, sprowadzając sie tylko do prawdziwych detekcji.
5. We Frigate’cie bardzo istotnym jest optymalizacja parametrów stref, mask obiektów, min_area, max_area i innych które wykluczają fałszywe detekcje osób - np. mi wielokrotnie tuje wykrywa jako osobę. Niestety Frigate’a trzeba non stop konfigurować wykluczając strefy, modyfikując parametry. Naszym celem jest zmniejszenie ilości zdarzeń “osoba”, sprowadzając sie tylko do prawdziwych detekcji.
![]() 6. W kamerach Reolink’a polecam strumienie RTSP. Strumień http-flv działa wyłacznie dla 5MP kamer a i tak jest niestabilny. Jeśli macie nagrywarkę Reolink NVR, warto pociągać strumienie z NVRa zamiast wprost z kamery, odciąży to CPU kamery.
6. W kamerach Reolink’a polecam strumienie RTSP. Strumień http-flv działa wyłacznie dla 5MP kamer a i tak jest niestabilny. Jeśli macie nagrywarkę Reolink NVR, warto pociągać strumienie z NVRa zamiast wprost z kamery, odciąży to CPU kamery.
![]() 7. FFMPEG presety - próbowałem je wszystkie, włącznie z ręcznym dłubaniem przy parametrach. Celem była redukcja użycia CPU. Efekt? Dla mnie działają te:
7. FFMPEG presety - próbowałem je wszystkie, włącznie z ręcznym dłubaniem przy parametrach. Celem była redukcja użycia CPU. Efekt? Dla mnie działają te:
Per-kamera:
output_args:
record: preset-record-generic-audio-aac
Ogólne:
ffmpeg:
global_args: -hide_banner -loglevel debug
hwaccel_args: preset-vaapi
input_args: preset-rtsp-restream
![]() 8. Aby zmniejszyć użycie CPU, warto ograniczyć ilość zmian rozdzielczości. W tym celu, we Frigate ustawiamy per-camera wartości width x height odpowiadające strumieniowi:
8. Aby zmniejszyć użycie CPU, warto ograniczyć ilość zmian rozdzielczości. W tym celu, we Frigate ustawiamy per-camera wartości width x height odpowiadające strumieniowi:
detect:
width: 3840
height: 2160
![]() 9. Dla najwyższej stabilności łącza polecam kamery PoE - kabel to kabel.
9. Dla najwyższej stabilności łącza polecam kamery PoE - kabel to kabel.
![]() 10. Z moich testów wynika, że detekcja twarzy najczęściej występuje na zdjęciach pochodzących z latest oraz snapshot - mniej więcej po równo (więcej mam detekcji z latest). To oznacza, że zdjęcie pobierane ze zdarzenia MQTT Frigate’a - u mnie - nie prowadzi praktycznie nigdy do detekcji. To oznacza, że bezpiecznie można wyłączyć opcję “mqtt” w Double-Take YAMLu.
10. Z moich testów wynika, że detekcja twarzy najczęściej występuje na zdjęciach pochodzących z latest oraz snapshot - mniej więcej po równo (więcej mam detekcji z latest). To oznacza, że zdjęcie pobierane ze zdarzenia MQTT Frigate’a - u mnie - nie prowadzi praktycznie nigdy do detekcji. To oznacza, że bezpiecznie można wyłączyć opcję “mqtt” w Double-Take YAMLu.
Zaoszczędzi to nieco taktów CPU. Ja w przykładzie wklejonym powyżej zostawiam, może u kogoś zadziała.
![]() 11. Klipy z Frigate’a zapisuj do katalogu na serwerze który uruchamia Frigate’a (lokalnie). Nie używaj podmontowanego udziału SMB/CIFS/Samba, ani NFS.
11. Klipy z Frigate’a zapisuj do katalogu na serwerze który uruchamia Frigate’a (lokalnie). Nie używaj podmontowanego udziału SMB/CIFS/Samba, ani NFS.
Unikniesz problemu “Unable to keep up with…” gdzie Frigate nie nadąża zapisywać klipów z uwagi na ograniczone I/O dysku. Miałem ten problem bo chciałem od razu na NASa wrzucać nagrania. Niestety, trzymam nagrania na NUCu, a później rsync’iem wysyłam na NASa ![]()
![]() 12. We Frigate’cie nie rozbijaj strumienia “detect” i “record” na osobne połączenia do kamery. W sekcji Go2Rtc skonfiguruj “jedną” linię połączenia (np. RTSP) i daj jej wszystkie role (detect, record, audio).
12. We Frigate’cie nie rozbijaj strumienia “detect” i “record” na osobne połączenia do kamery. W sekcji Go2Rtc skonfiguruj “jedną” linię połączenia (np. RTSP) i daj jej wszystkie role (detect, record, audio).
Mniejsza ilość połączeń do kamery odciąży CPU kamery. CPU kamery z reguły ledwo wystarcza na jej własne potrzeby.
Spójrz w moim configu jak mam zrealizowaną sekcję go2rtc. Zauważ tylko jedno połączenie z danym IP kamery.
Dokumentacja Frigate’a na ten temat:
![]() 13. Aby sprawdzić czy strumień który podajesz w konfiguracji Frigate’a w sekcji “go2rtc” działa poprawnie i jakie są jego parametry, uruchom linię poleceń i zaloguj się do docker Frigate’a:
13. Aby sprawdzić czy strumień który podajesz w konfiguracji Frigate’a w sekcji “go2rtc” działa poprawnie i jakie są jego parametry, uruchom linię poleceń i zaloguj się do docker Frigate’a:
bash # docker exec -it frigate /bin/bash
A następnie użyj polecenia ffprobe podając jako jego pierwszy argument całą linię wskazującą na strumień kamery, np. u mnie:
frigate # ffprobe "rtsp://username:password@192.168.X.Y:554/h264Preview_01_main"
Wyjście tego polecenia pokaże Ci parametry audio, rozdzielczość strumienia i czy w ogóle to działa ![]()
![]() 14. Jak trenować te sieci aby rozpoznały twarz?
14. Jak trenować te sieci aby rozpoznały twarz?
- Korzystamy z interfejsu Double-Take:
– 1. wchodzimy w kartę train
– 2. lewy górny róg rozwijane menu - wybieramy “add new”
– 3. wpisujemy nazwe osoby (tzw. etykieta)
– 4. wgrywamy zdjęcia danej osoby
– 5. Każde wgrane zdjęcie “dotrenowuje” sieć.
Jeśli chcemy zmienić backend detekcyjny - klikamy “Sync”, spowoduje to usunięcie twarzy i wytrenowanie od początku.
![]() 15. Jakie zdjęcia się nadadzą do treningu?
15. Jakie zdjęcia się nadadzą do treningu?
-
Po pierwsze, na podstawie researchu, czytania porad osób, różnych projektów (typu YOLOv5) nie zawsze więcej = lepiej.
-
Lepiej mieć ograniczoną ilość zdjęć (np. 30-50 zdjęć osoby), ale lepszej jakości niż wgrać 1000 bzdurnych fotek.
-
Zdjęcie powinno przedstawiać twarz w całej okazałości, najlepiej frontalnie, w dobrym oświetleniu.
-
Podczas treningu modele wyciągają “cechy” twarzy, np:
– rozstaw oczu (dystans)
– rozmieszczenie kości policzkowych
– geometria czoła, oczodołów, ust, nosa -
Te cechy muszą być pobrane ze zdjęć twarzy, a nie sylwetki.
-
Wysyłamy więc zdjęcia typu “Selfie” - a nie zdjęcie na tle drzewa czy Schodów Smoleńskich.
-
Ja mam po 30 zdjęć swoich i żony i to nadal za mało, jak widzicie na screenshot’cie - na kilku zdjęciach wykryło nas jak “Unknown”

To chyba na tyle z pierwszych myśli jakie przyszły do głowy, zapraszam do dyskusji ![]()
Zapraszam również CPU-sceptyków i GPU-wyznawców - chętnie zmierzę się z Waszymi przekonaniami.
PS: U mnie działa. ![]() To że u mnie działa nie znaczy że u Ciebie zadziała.
To że u mnie działa nie znaczy że u Ciebie zadziała.
Cały ten opis aplikuję do mojej platformy.
![]() Spodobał Ci się mój opis?
Spodobał Ci się mój opis?
Sprawdź mój setup Home Assistanta dla inspiracji i dla garści innych porad:
8 polubień
Nie sprawdzę bo nie mam (i nie zamierzam mieć) FB ale to mój wybór ![]() ale i tak szacun za spędzony czas na testach i dawkę cennych informacji.
ale i tak szacun za spędzony czas na testach i dawkę cennych informacji.
Widziałem ten post i można powiedzieć że doktoryzowałeś się z Frigate. Bardzo fajnie że podzieliłeś się tą wiedzą ![]()
1 polubienie
witam wszystkich mam mini pc fujitsu esprimo q556/2 procesor i3-6100t 3.2 GHZ grafika mesa intel hd 530. Mam pytanie jest sens instalować home assistant z frigate czy lepiej coś szukać innego dokupię Google coral tpu usb docelowo będzie 3 kamery.
Skoro już go masz to wykorzystaj, a jeśli się okaże, że jest za slaby na twoje wymagania, to wtedy będziesz wiedział czego potrzebujesz docelowo.
Dzieki za odpowiedz tylko ostatnie pytanie jak zainstalować HA na takim komputerze. Czytałem ze w dokerze ale żeby działał razem z frigate to już nie wiem.
Ja bym najpierw spróbował tak (Frigate istnieje też jako Dodatek oraz komponenty niestandardowe)
https://forum.arturhome.pl/t/instalacja-natywna-bare-metal-golas-home-assistant-os-haos-generic-koncowka-2022/3777/
ale jeśli zjadłeś zęby na Dockerze, to oczywiście jest to elastyczniejsza metoda
Do przechowywania zapisów video dobrze jest przeznaczyć osobny, klasyczny dysk HDD.
SSD pomimo, że szybki na rejestrator się nie nadaje.
1 polubienie
W SambaNAS samba-nas można sobie podmontować dodatkowe nośniki lokalne (trochę na okrętkę bo jako zasoby sieciowe, ale cel jest do osiągnięcia).
Mam mini pc fujitsu esprimo q556/2 chce kopić Google Coral lepiej kupic na usb czy taki : Google Coral M.2 Accelerator A+E key - G650-04527-01