Takie hece przy instalacji wg. filmu Artura:
Instalacja na HP t620 (4 cores), 10GB ram. Ktoś ma jakiś pomysł?
///mod edit:
Wątek źródłowy
https://forum.arturhome.pl/t/instalacja-home-assistant-na-proxmox-w-2021-roku/1497/45
Takie hece przy instalacji wg. filmu Artura:
///mod edit:
Wątek źródłowy
https://forum.arturhome.pl/t/instalacja-home-assistant-na-proxmox-w-2021-roku/1497/45
No ja bym sprawdził sprzęt najpierw - otwórz budę i zobacz czy jest radiator na procesorze ![]() potem jakiś memtest
potem jakiś memtest
i/lub
Ale to jest sprzęt, na którym mój HA działał przez ponad rok, tylko w dockerze, a teraz na Proxmoxie od początku wszystko instaluję, więc chyba sprzęt powinien być ok.
Jak żyję zwisy rdzenia widziałem tylko w 2 wypadkach:
To jednak nie to, ten procesor nie ma radiatora i przeprowadziłem 2-godzinny memtest - zero błędów.
Włożyłem też dysk ze starą konfiguracją w dockerze i wszystko gra. Czyli procesor powinien być ok.
No zapewne nie było to dobre trafienie, skoro sprzęt działał wcześniej poprawnie.
Jeśli wirtualizacja nie jest musem, spróbuj instalacji natywnej (choć wtedy pewnie RAM się będzie marnował).
Poza konkurencją (skoro już wiemy, że intuicja mnie zawiodła):
ad 1) kliknąłem po prostu Start test i przeprowadziłem go tylko na jednej konfiguracji. Zauważyłem jednak pewną dziwną prawidłowość po upgrade ramu z 6Gb do 10GB - pamięć bardzo szybko zapycha się i ilość dostępnej spada czasem nawet do poniżej 1GB (mowa o wcześniejszej instalacji w dokerze).
ad 2) miałem na myśli radiator, bo go nie widzę, ale zobaczyłem dziś to zdjęcie:
Czy wirtualizacja jest musem? Pewnie nie, bo nie zamierzam tworzyć innych wirtualek, niż ta dla HA, ale jaka jest alternatywa, skoro instalacja w dockerze jest “unsupported”? Nie znam się za bardzo na tych różnych wersjach instalacji, podążam trochę za tłumem, bo teraz wszyscy instalują HA na Proxmoxie.
He he, no nie “coś tam”, tylko ogromny radiator wielkości całego urządzenia z 2 sporymi ciepłowodami, jakkolwiek hipotezę o problemie z chłodzeniem wstępnie odrzucam - skoro to jest sprzęt który używałeś dłuższy czas bez problemów (mimo wszystko pierwsze co bym zrobił w kilkuletnim polizingowcu to kontrola stanu chłodzenia + ewentualna wymiana pasty)
Temperatura bardzo w porządku, ale nie monitorujesz zegara, a dopiero wtedy widać, gdzie jest punkt krytyczny (wtedy widać czy i kiedy throttluje).
Podstawowa alternatywa to instalacja “natywna” (bare metal) HAOS
nikomu się chyba nie chciało dotąd napisać tutoriala, bo stopień komplikacji jest praktycznie zerowy - po prostu przepisujemy obraz systemu na nośnik (w tym wypadku ssd UWAGA to nadpisuje cały dysk) za pomocą Balena Ether lub dd.
I to wszystko, resztę robi skrypt instalacyjny przy pierwszym uruchomieniu (ale to nikogo nie interesuje, “bo dzieje się samo”).
Pewną komplikacją jest używanie więcej niż jednego hdd, ale od aktualnej wersji systemu, jest zawarty w systemie skrypt który przeniesie partycję danych na inny nośnik niż ten używany do bootowania (gdzieś to już opisywałem, UWAGA to nadpisuje cały drugi dysk) - w ten sposób można wykorzystać jakiś śmiesznie mały ssd (zwykle fabrycznie montowany w TC) jako dysk systemowy, a drugi większy mieć tylko na dane (druga zaleta takiej dwu-dyskowej instalacji - ten “maluch” nie będzie się praktycznie zużywał, bo w zasadzie tylko aktualizacje systemu będą na nim zapisywane).
Edit - kwestia drugiego dysku (dla instalacji “bare metal”) w końcu jest w podstawowej dokumentacji:
Jest jeszcze jedna kwestia
o ile zużycie całej dostępnej pamięci nie jest zasadniczo niczym anormalnym w przypadku większości systemów, to jednak w przypadku HA bym się nad tym zastanowił i przyjrzał się szczegółowiej jakie procesy “żrą” pamięć (tak naprawdę w typowej instalacji nie ma co zjadać takich ilości RAMu, w dodatku większość instalacji HA to systemy mające co najwyżej 1GB)
Można w takim wypadku zacząć monitorować wykorzystanie swap (dopóki jest 0% nie ma powodu do niepokoju).
Monitorować nie znaczy raz zajrzeć - zrób sobie sensory i wykresy (a za klika dni zrestartuj hosta), w każdym razie masz niezerowe użycie swap (to jeszcze nie jest tragedia, ale oznacza, że były momenty gdy wykorzystanie RAM przekroczyło wartość swappiness), a można ją podejrzeć np. tak:
cat /proc/sys/vm/swappiness
wynikiem jest liczba oznaczająca % wolnej pamięci poniżej którego zawartość RAM zacznie być spychana do swap.
Czy swappiness ma znaczenie tylko w przypadku instalacji na Proxmox? Bo tę, póki co, wstrzymałem ze względu na błędy, o których wcześniej wspomniałem. Obecnie w/w polecenie zwraca mi wartość 60.
To jest wartość, którą można ustawić samodzielnie w większości linuxów o ile tylko masz prawa roota (więc nie w HAOS), 60 jest raczej standardowo, ale jeśli jest jakiś problem to tu go nie szukaj - zrzucanie pamięci do swap jest normalne, jeśli gdzieś jest problem to dotyczy on wykorzystania RAMu - przy takiej ilości pamięci swap nie powinien być używany wcale (no chyba , że jakiś proces to spowoduje - ostatnio przyczyną mogła być np. naprawa bazy danych po zmianie czasu - no cóż twórcy HA coś sknocili, ale zazwyczaj anormalnie duże wykorzystanie RAMu wynika z tzw. wycieku pamięci - jakiś proces jej nie zwalnia prawidłowo, co ostatecznie w najgorszym wypadku kończy się zajęciem całej pamięci i wywrotką systemu).
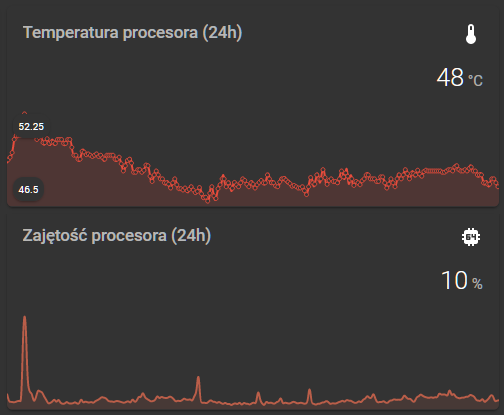
Wycieki pamięci widać na wykresie - po prostu wykorzystanie systematycznie idzie w górę.
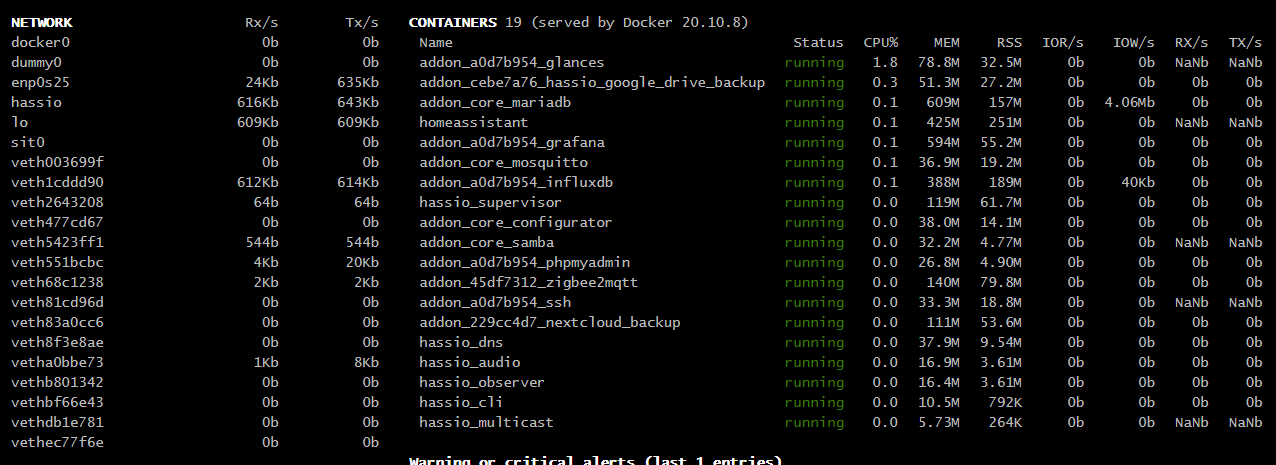
wygląda to zwykle jakoś tak (obrazek zapożyczyłem z innego wątku)
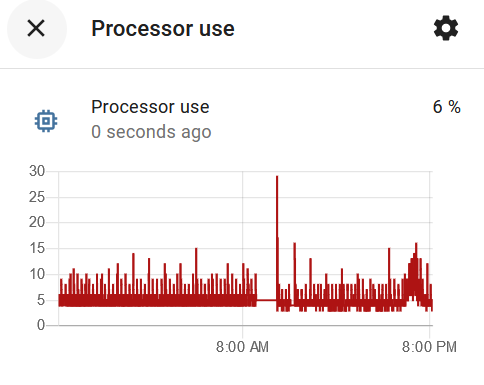
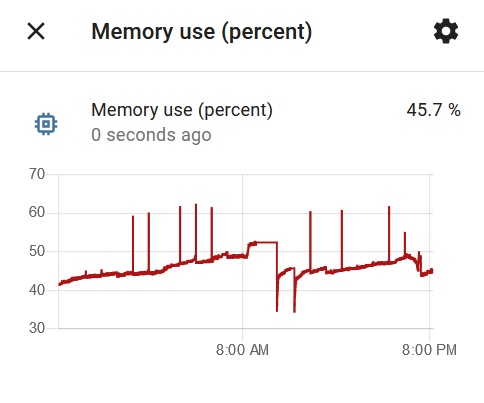

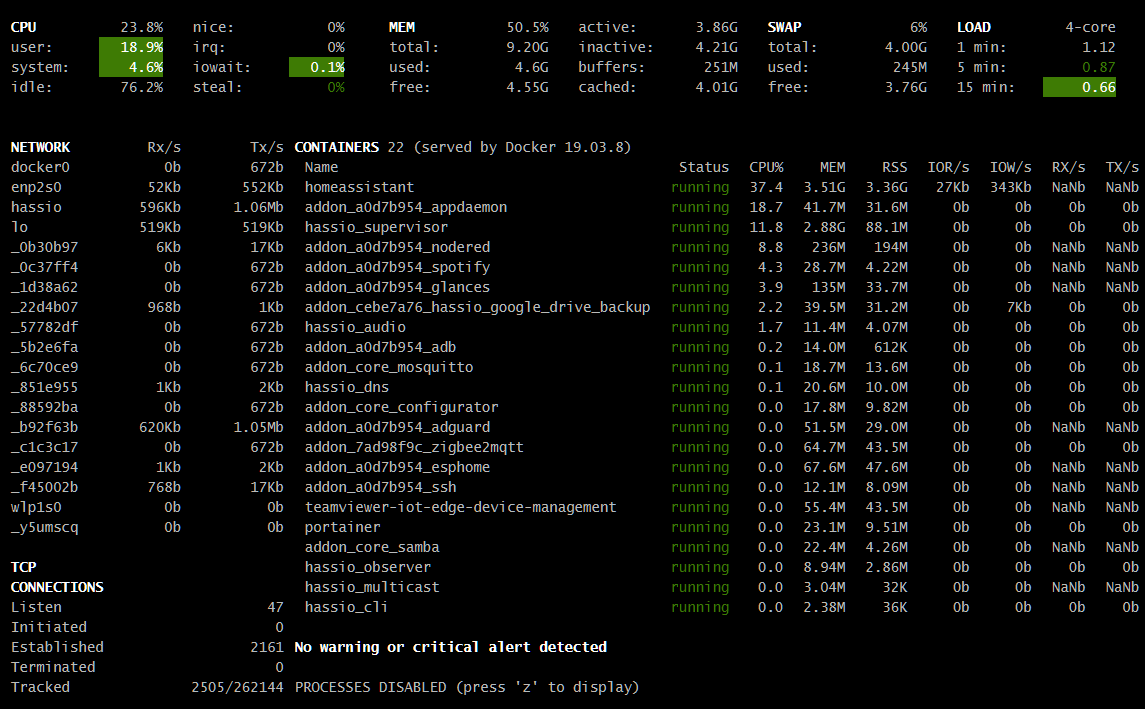
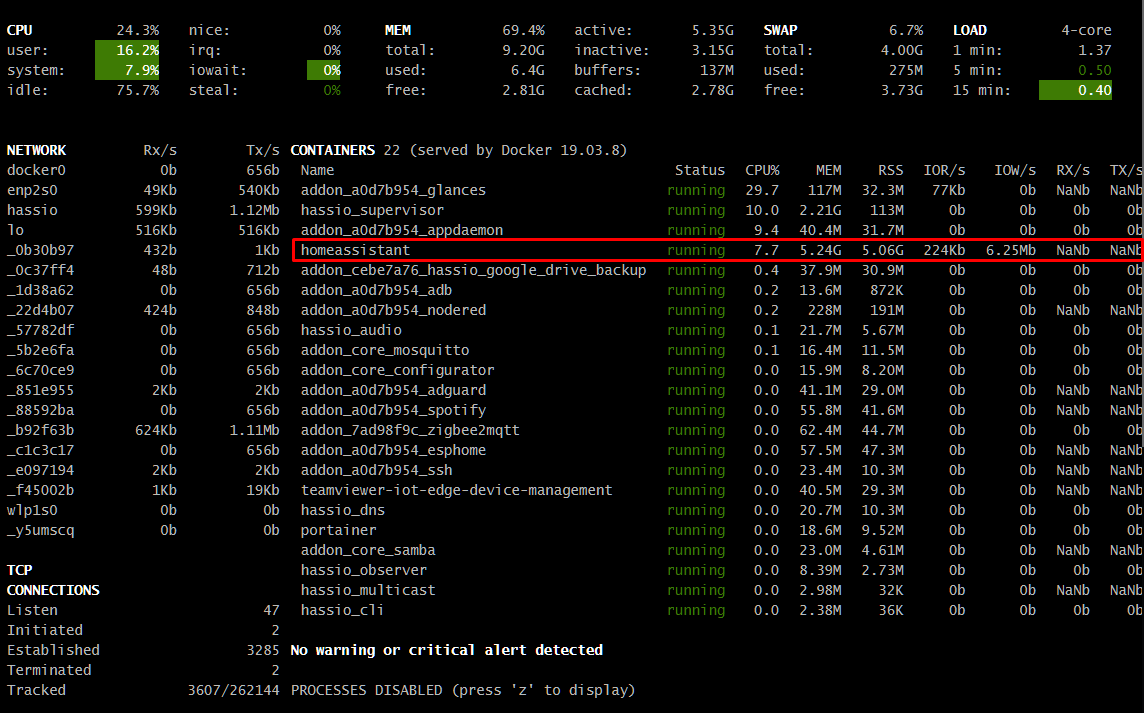
Zwróć uwagę na całkowitą odwrotność u Ciebie - CPU jest zajęty i to bardzo jakimś Twoim procesem.
Dla porównania RAM - fakt że mam go więcej.
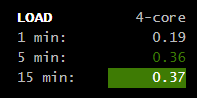
I obciążenie CPU - u Ciebie kosmiczne jednostki.
I co pożera zasoby:
Tu opisałem Instalacja na INTEL NUC i nie tylko ( posiłkuj się też Wpisem @szopen ) jak się to instaluje natywnie.
Forumowicze przeważnie mają NAS-y i dlatego przykładowo stawiają HA na PROXMOXIE aby nie marnować zasobów bo NAS robi jeszcze inne rzeczy.
Nie wiem z czym porównujesz - to cudzy screenshot tylko w celu prezentacji jak wygląda wyciek pamięci, a w jednej ze swoich instalacji świadomie zajmuję cały procek (jeśli nawiązujesz do jakiegoś wcześniej wrzuconego mojego obrazka z Glances).
Aj sorry nie zauważyłem, że piszesz do @Piotr_K ![]()
W każdym razie potwierdzam - HA zajmuje niesamowicie dużo
Hehe pomyłka - myślałem, że chodzi o zapożyczony obrazek (ten dla wizualizacji wycieku pamięci).
W każdym razie “na dzień dobry” podejrzana jest baza danych - warto zobaczyć jaki ma rozmiar plik ją zawierający (jeśli to jest standardowa baza). W instalacji gdzie mam ją dość mocno zaniedbaną HA zajmuje mi jakieś 2,5GB RAMu.
Jak na moje oko to i supervisor zajmuje jakieś kosmiczne zasoby.
Z drugiej strony - przy bardzo rozbudowanej instalacji faktycznie zużyte zasoby mogą być spore.
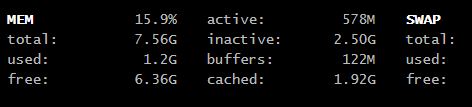
Wiesz, masz procesor bijący na głowę mój prawie pod każdym względem (poza TDP), jednak screen, który podrzuciłem, nie jest miarodajny, bo taki duży wzrost obciążenia powoduje właśnie dodatek Glances. Normalnie mam obciążenie na poziomie 10%. Ramu nie masz więcej, bo mam 10GB, ale martwi mnie jego zajęcie. Gdy miałem 6GB, to miałem 4 wolnego, a teraz mam 10GB i nadal 4 wolnego, a bywa że zostaje poniżej 1GB i muszę resetować maszynę. Procesy hassio_supervisor i homeassistant to chyba przesada.
Tak, to mój odczyt
Baza ma 1,5GB, też mam w niej burdel. W nowej instalacji zamierzałem już zrobić z nią porządek, porobić excludy itp.
Ale zachęciłeś mnie do wersji Generic x86-64, jutro spróbuję się z nią zmierzyć, jeżeli robota pozwoli.
Dlatego sugerowałem stworzenie wykresów, jeśli masz Glances to można wykorzystać utworzone przez niego encje (masz to zapewne nie od dzisiaj zainstalowane, więc dysponujesz historią).
Podstawowe monitorowanie systemu można ogarnąć też bez Glances (oczywiście przedstawiona konfiguracja pasuje w całości tylko do mojego sprzętu, więc trzeba odpowiednio to zmodyfikować), nie wiem czy to zadziała wewnątrz VM (to info dla użytkowników Proxmoxa i innych wirtualek).
sensor:
- platform: command_line
name: ACPI Temperature
command: "cat /sys/class/thermal/thermal_zone0/temp"
unit_of_measurement: "°C"
value_template: '{{ value | multiply(0.001) | round(1) }}'
- platform: command_line
name: CPU Temperature
command: "cat /sys/class/thermal/thermal_zone1/temp"
unit_of_measurement: "°C"
value_template: '{{ value | multiply(0.001) | round(1) }}'
- platform: systemmonitor
resources:
- type: disk_use_percent
arg: /home
- type: disk_use
arg: /home
- type: disk_free
arg: /home
- type: swap_use_percent
- type: swap_use
- type: swap_free
- type: memory_use_percent
- type: memory_free
- type: memory_use
- type: processor_use
- type: load_1m
- type: load_15m
- type: processor_temperature
- type: last_boot
- type: ipv4_address
arg: enp1s0
- type: ipv6_address
arg: enp1s0
- platform: cpuspeed
Sensory zrobiłem dopiero wczoraj, Glances uruchamiam tylko czasami (zbyt duże zużycie zasobów przez ten dodatek), więc historii nie mam. Dziś znów spuchł mi proces HA: